

Miglioramento del rilevamento nei modelli Transformer aggiungendo rumore di addestramento
I moderni modelli di visione a trasformatore aggiungono rumore per migliorare le prestazioni di rilevamento di oggetti 2D e 3D. In questo articolo, scopriremo come funziona questo meccanismo e discuteremo il suo contributo al miglioramento dell'accuratezza dei modelli di rilevamento di oggetti, concentrandoci sull'uso di tecniche come la riduzione del rumore nel processo di addestramento.

Modelli trasformatori per la visione precoce
DETR – DEtection TRansformer (Carion, Massa et al., 2020), una delle prime architetture Transformer per il rilevamento di oggetti, utilizzava query di codifica-decodifica apprese per estrarre informazioni di rilevamento dai token immagine. Queste query venivano inizializzate in modo casuale e l'architettura non imponeva alcun vincolo che le obbligasse ad apprendere oggetti simili ad ancore. Pur ottenendo risultati simili a Faster-RCNN, il suo svantaggio era la lenta convergenza: erano necessarie 500 epoche per addestrarlo (DN-DETR, Li et al., 2024). Le architetture più recenti basate su DETR utilizzavano il pooling deformabile che consentiva alle query di concentrarsi solo su regioni specifiche dell'immagine (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), mentre altre (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) utilizzavano ancore spaziali (generate utilizzando k-means, in modo simile a come fanno le CNN basate su ancore), che venivano codificate nelle query iniziali. Le connessioni di salto forzavano il blocco decodificatore Transformer ad apprendere le caselle come valori di regressione dalle ancore. I livelli di attenzione deformabili utilizzavano le ancore precodificate per campionare le caratteristiche spaziali dall'immagine e utilizzarle per generare token di attenzione. Durante l'addestramento, il modello apprende le ancore ottimali da utilizzare. Questo approccio insegna al modello a utilizzare esplicitamente caratteristiche come la dimensione della casella nelle sue query.
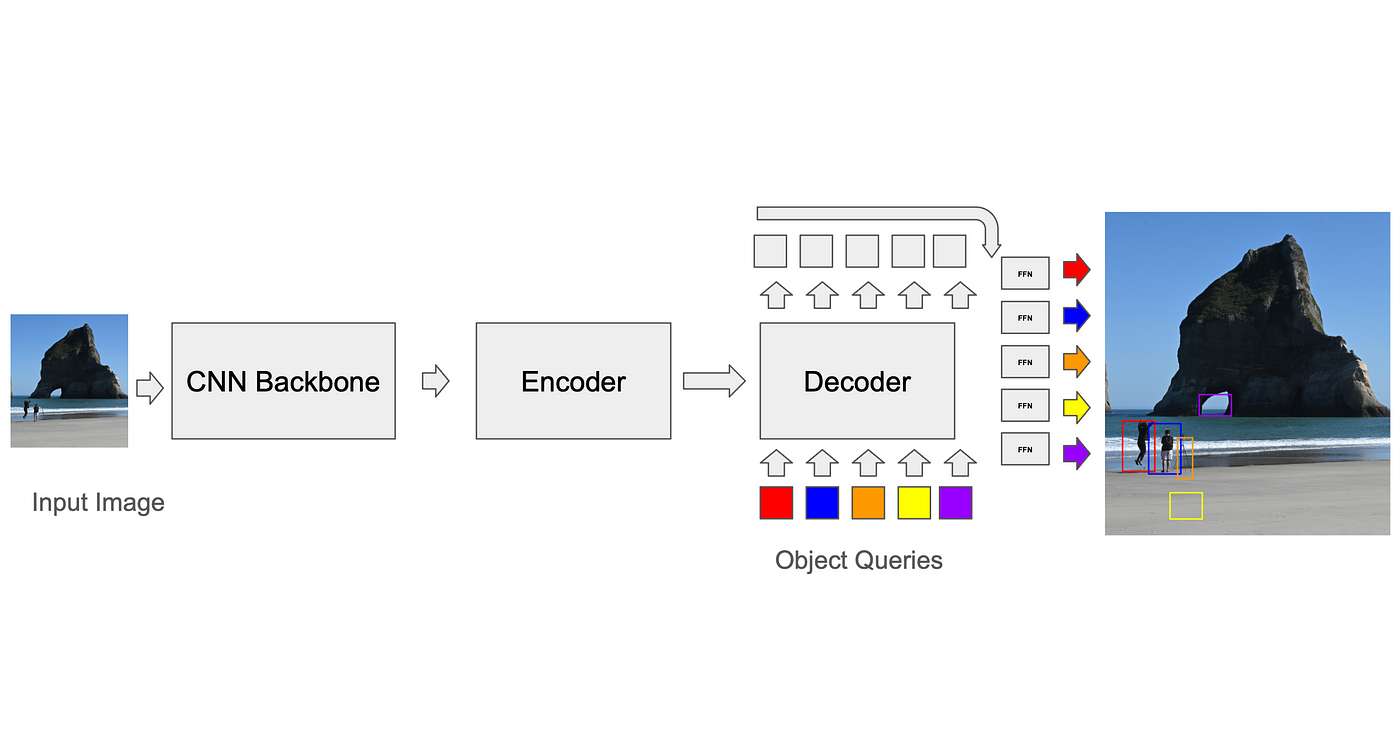
Corrispondenza delle previsioni con i fatti concreti: algoritmo di corrispondenza binaria
Per calcolare la perdita, il trainer deve prima abbinare le previsioni del modello alle caselle di verità di base (GT). Mentre le CNN basate su anchor hanno soluzioni relativamente semplici a questo problema (ad esempio, ogni anchor può essere abbinata solo alle caselle GT nel suo voxel durante l'addestramento e l'inferenza, la soppressione non massima viene utilizzata per rimuovere le rilevazioni sovrapposte), lo standard per i trasformatori, sviluppato dal DETR, consiste nell'utilizzare un algoritmo di matching binario chiamato algoritmo ungherese. In ogni iterazione, l'algoritmo trova la migliore corrispondenza tra la previsione e la verità di base (una corrispondenza che ottimizza una funzione di costo, come la distanza quadratica media tra gli angoli delle caselle, sommata su tutte le caselle). La perdita tra le coppie previsione-terra-verità viene quindi calcolata e può essere retropropagata. Le sovraprevisioni (previsioni senza matching GT) comportano una perdita separata che le porta ad abbassare il loro punteggio di confidenza. Questo processo è essenziale per migliorare l'accuratezza del modello e ridurre gli errori.
il problema
La complessità temporale dell'algoritmo ungherese è o(n³). È interessante notare che questo non rappresenta necessariamente un collo di bottiglia nella qualità dell'addestramento: The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective, Fenoaltea et al., 2021, mostra che l'algoritmo è instabile, il che significa che una piccola modifica nella sua funzione obiettivo può portare a una grande modifica nel suo risultato di matching, portando a obiettivi di addestramento delle query incoerenti. Le implicazioni pratiche nell'addestramento dei trasformatori sono che le query degli oggetti possono saltare da un oggetto all'altro, impiegando molto tempo per apprendere le migliori caratteristiche per la convergenza. In altre parole, l'instabilità dell'algoritmo porta a oscillazioni nel processo di addestramento, richiedendo tempi più lunghi per raggiungere risultati ottimali.
DN-DETR (Rilevamento di oggetti mediante eliminazione del rumore)
Li et al. hanno proposto una soluzione elegante al problema dell'abbinamento instabile, che è stata poi adottata in molti altri lavori, tra cui DINO, Mask DINO, Group DETR e altri.
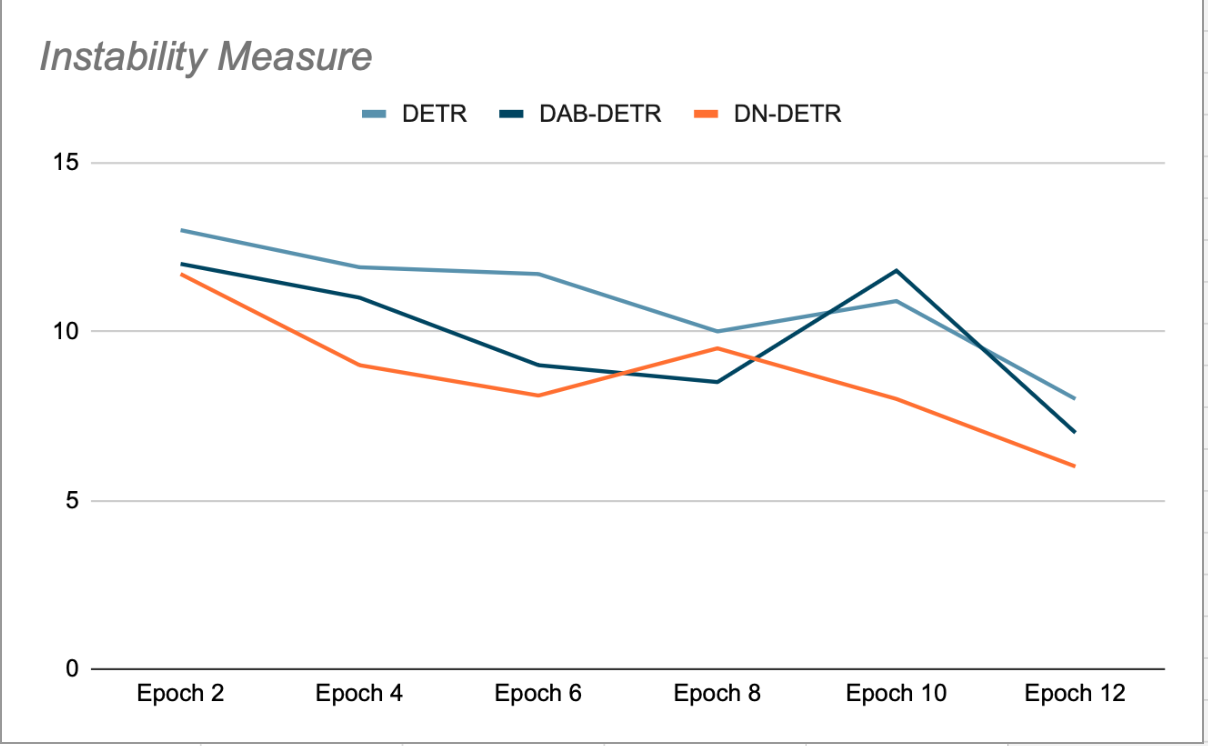
L'idea principale del DN-DETR è quella di migliorare la formazione creando Punti di articolazione immaginari facili da inclinareSaltando il processo di matching, questo viene fatto durante l'addestramento aggiungendo una piccola quantità di rumore alle tessere GT (terreno reale) e alimentando queste tessere rumorose come ancore per le query del decoder. Le query DN vengono mascherate dalle query organiche e viceversa, per evitare attenzioni incrociate che potrebbero interferire con l'addestramento. I rilevamenti generati da queste query sono già abbinati alle loro tessere GT di origine e non richiedono un matching bipartito. Gli autori di DN-DETR hanno dimostrato che durante le fasi di validazione alla fine di ogni epoca (in cui la rimozione del rumore è disattivata), questo migliora la stabilità del modello rispetto a DETR e DAB-DETR, il che significa che le query Plus sono coerenti nel loro matching con l'oggetto GT nelle epoche successive (vedi Figura 2).
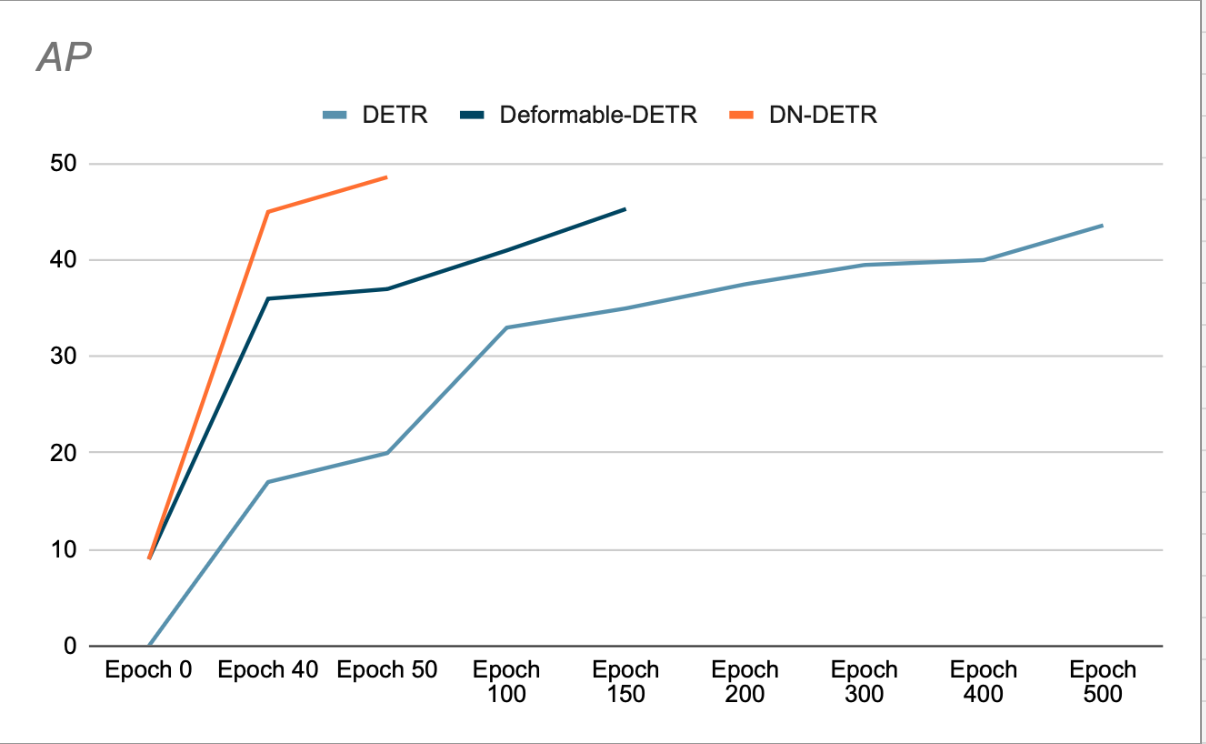
Gli autori dimostrano che l'utilizzo di DN accelera la convergenza e consente di ottenere risultati di rilevamento migliori (vedere Figura 3). Il loro studio di rimozione mostra un aumento dell'1.9% dell'AP (accuratezza media) sul set di dati di rilevamento COCO, rispetto al precedente SOTA (DAB-DETR, AP 42.2%), utilizzando ResNet-50 come backbone.
DINO e rimozione del rumore di contrasto
DINO sviluppa ulteriormente questa idea, aggiungendo l'apprendimento contrastivo al suo meccanismo di denoising: oltre all'esempio positivo, DINO crea una seconda versione denoised di ogni GT, costruita matematicamente per essere più lontana dal GT rispetto all'esempio positivo (vedi Figura 4). Questa versione viene utilizzata come esempio negativo per l'addestramento: il modello impara ad accettare rilevazioni più vicine alla verità di base e a rifiutare rilevazioni più lontane (imparando a predire la classe "nessun oggetto").
Inoltre, DINO consente il clustering multiplo per la denoising contrastiva (CDN), ovvero più ancore rumorose per ogni oggetto GT, ottenendo il massimo da ogni iterazione di addestramento.
Gli autori del DINO hanno segnalato una precisione media (AP) del 49% (su COCO val2017) quando si utilizza un CDN.
I moderni modelli temporali che devono tracciare oggetti da un frame all'altro, come Sparse4Dv3, utilizzano CDN e aggiungono gruppi di denoising temporale, in cui vengono memorizzati alcuni ancoraggi DN riusciti (insieme agli ancoraggi non DN appresi) per l'utilizzo nei frame successivi, il che migliora le prestazioni del modello nel tracciamento degli oggetti.

مناقشة
Il denoising (DN) sembra migliorare la velocità di convergenza e le prestazioni finali dei rivelatori a trasformatore di visione. Tuttavia, esaminando l'evoluzione dei vari metodi sopra menzionati, sorgono le seguenti domande:
- DN migliora i modelli che utilizzano ancore apprendibili. Ma le ancore apprendibili sono davvero importanti? E DN migliorerà anche i modelli che utilizzano ancore non apprendibili?
- Il contributo principale del DN all'addestramento è quello di aggiungere stabilità al processo di discesa del gradiente bypassando il matching bipartito. Tuttavia, il matching bipartito sembra esistere principalmente perché lo standard nel lavoro sui trasformatori è quello di evitare vincoli spaziali sulle query. Pertanto, se limitassimo manualmente le query a posizioni specifiche delle immagini e abbandonassimo il matching bipartito (o utilizzassimo una versione semplificata del matching bipartito, che viene eseguita separatamente su ciascuna patch di immagine), il DN migliorerebbe comunque i risultati?
Non sono riuscito a trovare alcun lavoro che fornisca risposte chiare a queste domande. La mia ipotesi è che un modello che utilizza ancore non apprendibili (a condizione che le ancore non siano troppo sparse) e query spazialmente vincolate: 1. non richiederà un algoritmo di matching binario e 2. non trarrà vantaggio dall'addestramento DN, poiché le ancore sono già note e non vi è alcun vantaggio nell'apprendere la regressione da altre ancore effimere.
Se le ancore sono fisse ma sparse, capisco come l'uso di ancore effimere faciliti la discesa e possa fornire un inizio caldo al processo di addestramento.
Anchor-DETR (Wand et al., 2021) confronta la distribuzione spaziale delle ancore apprendibili e non apprendibili e le prestazioni dei rispettivi modelli. A mio parere, l'apprendibilità non aggiunge un valore significativo alle prestazioni del modello. Vale la pena notare che entrambi i metodi utilizzano l'algoritmo ungherese, quindi non è chiaro se possano abbandonare il matching binario mantenendo comunque le prestazioni.
Una considerazione da tenere a mente è che potrebbero esserci ragioni produttive per evitare l'NMS nell'inferenza, il che incoraggia l'uso dell'algoritmo ungherese nella formazione.
Dove può davvero essere importante la cancellazione del rumore? A mio parere, in TracciabilitàNel tracciamento, il modello è dotato di un flusso video e il requisito non è solo quello di rilevare più oggetti in fotogrammi consecutivi, ma anche di mantenere l'identità univoca di ciascun oggetto rilevato. I modelli a trasformatore temporale, ovvero i modelli che sfruttano la natura sequenziale del flusso video, non elaborano i singoli fotogrammi in modo indipendente. Invece, mantengono una banca dati che memorizza le rilevazioni precedenti. Durante l'addestramento, il modello di tracciamento è incoraggiato a regredire dal rilevamento dell'oggetto precedente (o più precisamente, dall'ancora associata al rilevamento dell'oggetto precedente), piuttosto che semplicemente regredire dall'ancora più vicina. Poiché il rilevamento precedente non è vincolato da una rete di ancoraggi fissi, è plausibile che la flessibilità indotta dal DN sarà vantaggiosa. Mi piacerebbe molto leggere futuri lavori che affrontino questi problemi.
Questo è tutto sulla rimozione del rumore e il suo contributo ai trasformatori visivi! Se ti è piaciuto il mio articolo, ti invito a leggere anche altri miei articoli su deep learning e machine learning. visione artificiale!
I commenti sono chiusi.