

I segreti dell'intelligenza artificiale per il telefono di cui hanno bisogno gli appassionati: Gemini e ChatGPT raggiungono il massimo
Una delle tendenze più evidenti (e francamente più noiose) nel settore degli smartphone degli ultimi due anni è stato il continuo parlare di esperienze basate sull'intelligenza artificiale. In particolare, le aziende produttrici di silicio si vantano spesso di come i loro ultimi processori mobili consentiranno operazioni di intelligenza artificiale sui dispositivi, come la creazione di video.
Ci siamo già, anche se non del tutto. In mezzo a tutto il clamore che circonda i trucchi dell'intelligenza artificiale, che a volte risultano inefficaci per gli utenti di smartphone, la discussione raramente va oltre le vetrine appariscenti di nuovi processori e chatbot in continua evoluzione.
Solo quando l'assenza di Gemini Nano dal Google Pixel 8 ha destato scalpore, il pubblico ha scoperto l'importanza cruciale della capacità di RAM per l'intelligenza artificiale sui dispositivi mobili. Apple ha anche chiarito rapidamente che avrebbe limitato Apple Intelligence ai dispositivi con almeno 8 GB di RAM. Questa decisione riflette l'importanza della RAM nell'esecuzione efficiente dei modelli di intelligenza artificiale.
Ma l’immagine di un “telefono AI” non riguarda solo la capacità di memoria. L'efficacia con cui il tuo telefono esegue le attività basate sull'intelligenza artificiale dipende anche dalle ottimizzazioni invisibili della RAM e dallo spazio di archiviazione. E no, non parlo solo di capacità.
Le innovazioni in termini di memoria arrivano sui telefoni con intelligenza artificiale.

Digital Trends ha intervistato Micron, leader mondiale nelle soluzioni di memoria e storage, per analizzare il ruolo della RAM e dello storage nelle operazioni di intelligenza artificiale sugli smartphone. La prossima volta che acquisterai un telefono di lusso, dovresti tenere d'occhio i progressi di Micron.
Tra i prodotti più recenti dell'azienda con sede in Idaho figurano la memoria mobile UFS 9 NAND G4.1 e i moduli RAM LPDDR1X da 1γ (5-gamma) per gli smartphone di punta. In che modo queste soluzioni di memoria migliorano l'intelligenza artificiale sugli smartphone, oltre ad aumentarne la capacità?
Cominciamo con la soluzione di archiviazione NAND UFS 9 del G4.1. La promessa principale è un consumo energetico ridotto, una latenza ridotta e un'ampia larghezza di banda.. Lo standard UFS 4.1 può raggiungere velocità di lettura e scrittura sequenziali massime di 4100 MB/s, con un incremento del 15% rispetto alla generazione UFS 4.0, riducendo al contempo i valori di latenza.
Un altro vantaggio fondamentale è che le unità di archiviazione portatili di nuova generazione di Micron sono disponibili con capacità fino a 2 TB. Inoltre, Micron è stata in grado di ridurne le dimensioni, rendendolo una soluzione ideale per i telefoni pieghevoli e i telefoni sottili di nuova generazione come Galaxy bordo S25 Samsung.
Passando ai progressi della RAM, Micron ha sviluppato quelli che chiama moduli RAM LPDDR1X 5γ. Offre una velocità massima di 9200 MT/s, può contenere il 30% di transistor in più grazie alle dimensioni ridotte e consuma al contempo il 20% di energia in meno. Micron ha già introdotto la soluzione RAM 1β (1-beta) leggermente più lenta, presente nella serie di smartphone Samsung Galaxy S25.
L'interazione tra storage e intelligenza artificiale
Ben Rivera, direttore del product marketing della Mobile Business Unit di Micron, ha spiegato che Micron ha introdotto quattro miglioramenti chiave nelle sue ultime soluzioni di storage per garantire operazioni di intelligenza artificiale più rapide sui dispositivi mobili. Questi miglioramenti includono Zoned UFS, Data Deframmentation, Pinned WriteBooster e Intelligent Latency Tracker.
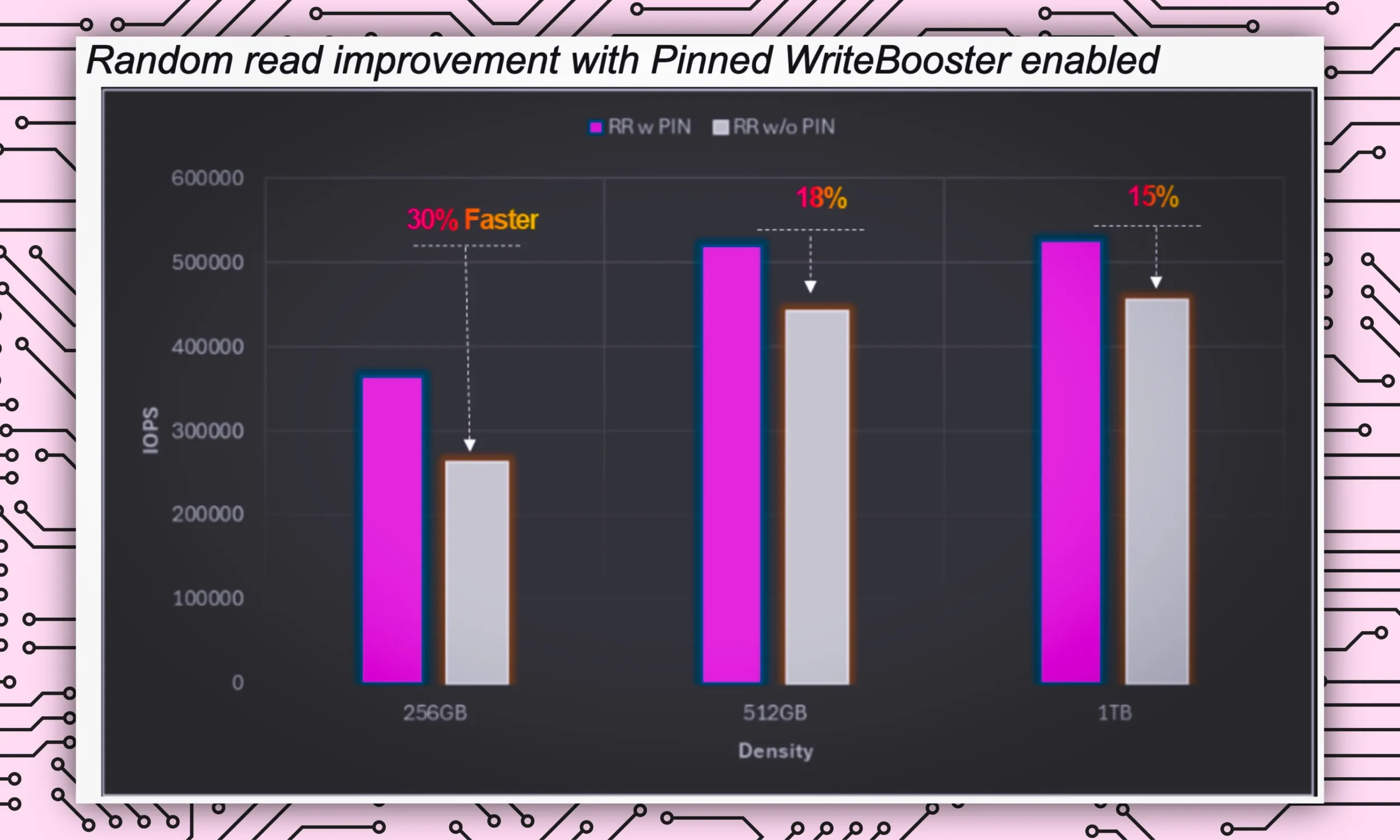
"Questa funzionalità consente al processore o all'host di identificare e isolare o 'fissare' i dati utilizzati più di frequente nello smartphone in un'area del dispositivo di archiviazione denominata buffer WriteBooster (simile a una cache) per consentirne un accesso rapido e immediato", spiega Rivera a proposito della funzionalità Pinned WriteBooster.
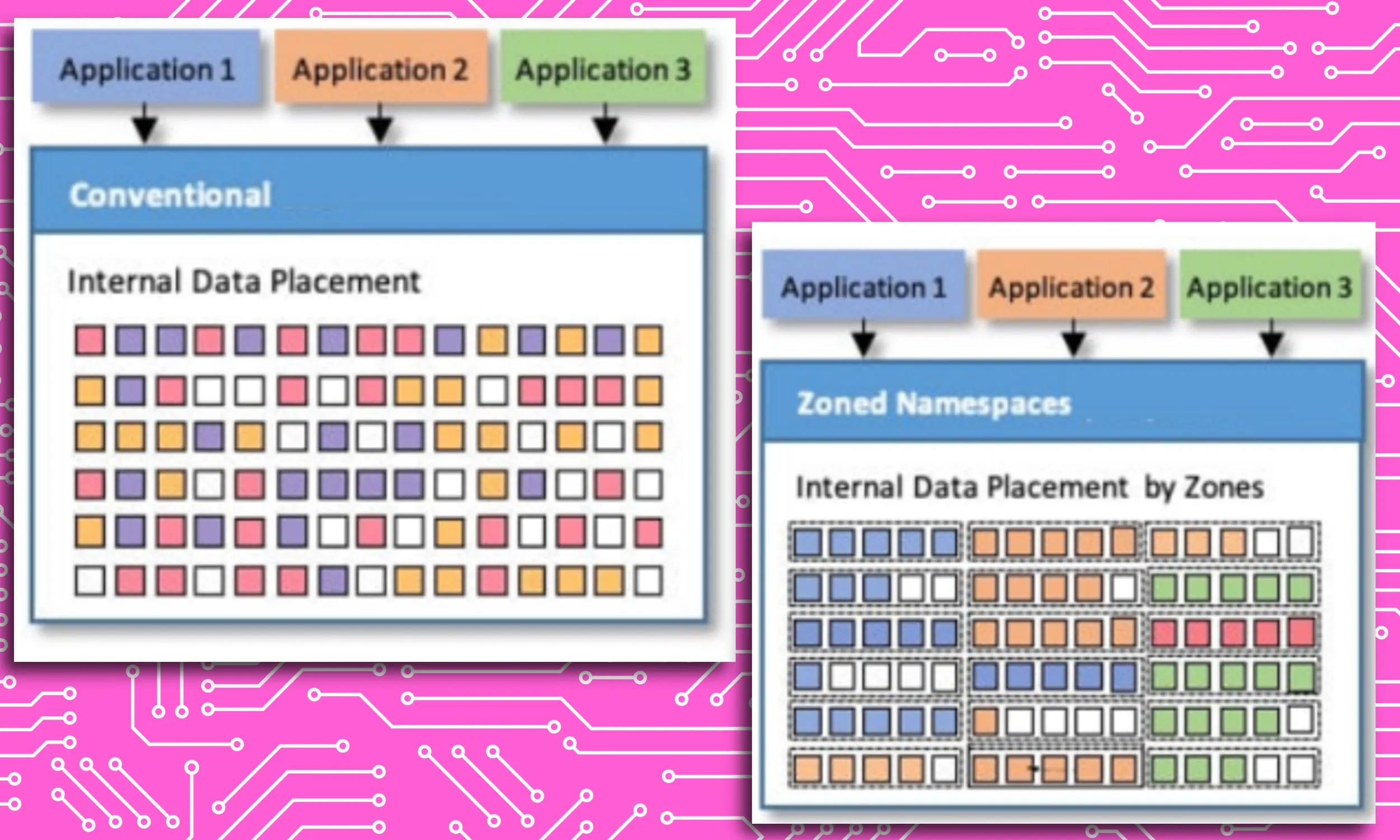
Ogni modello di intelligenza artificiale, come Google Gemini o ChatGPT, che cerca di eseguire attività su un dispositivo necessita del proprio set di file di istruzioni memorizzati localmente sul dispositivo mobile. Ad esempio, hai bisogno Apple Intelligence fino a 7 GB di spazio di archiviazione Per tutte le sue operazioni.
Per eseguire un'attività, non è possibile delegare l'intero stack di intelligenza artificiale alla RAM, poiché avrà bisogno di spazio per elaborare altre attività importanti, come effettuare chiamate o interagire con altre applicazioni importanti. Per far fronte ai limiti dell'archiviazione Micron, è stata creata una mappa di memoria che carica nella RAM solo i pesi AI richiesti dall'archiviazione.
Quando le risorse diventano limitate, ciò di cui si ha bisogno è uno scambio e una lettura dei dati più rapidi. In questo modo avrai la certezza che le attività di intelligenza artificiale verranno eseguite senza compromettere la velocità di altre attività importanti. Grazie a Pinned WriteBooster, questo scambio di dati viene accelerato del 30%, garantendo che le attività di intelligenza artificiale vengano elaborate senza alcun ritardo.
Supponiamo che tu abbia bisogno di Gemini per estrarre il file PDF per l'analisi. Lo scambio rapido della memoria garantisce che i pesi AI richiesti vengano trasferiti rapidamente dalla memoria alla RAM.
Successivamente abbiamo Data Defrag. Consideratelo come un organizer per scrivania o armadio, che garantisce che gli oggetti siano ordinatamente raggruppati in diverse categorie e riposti nei loro appositi armadietti, così da essere facili da trovare.
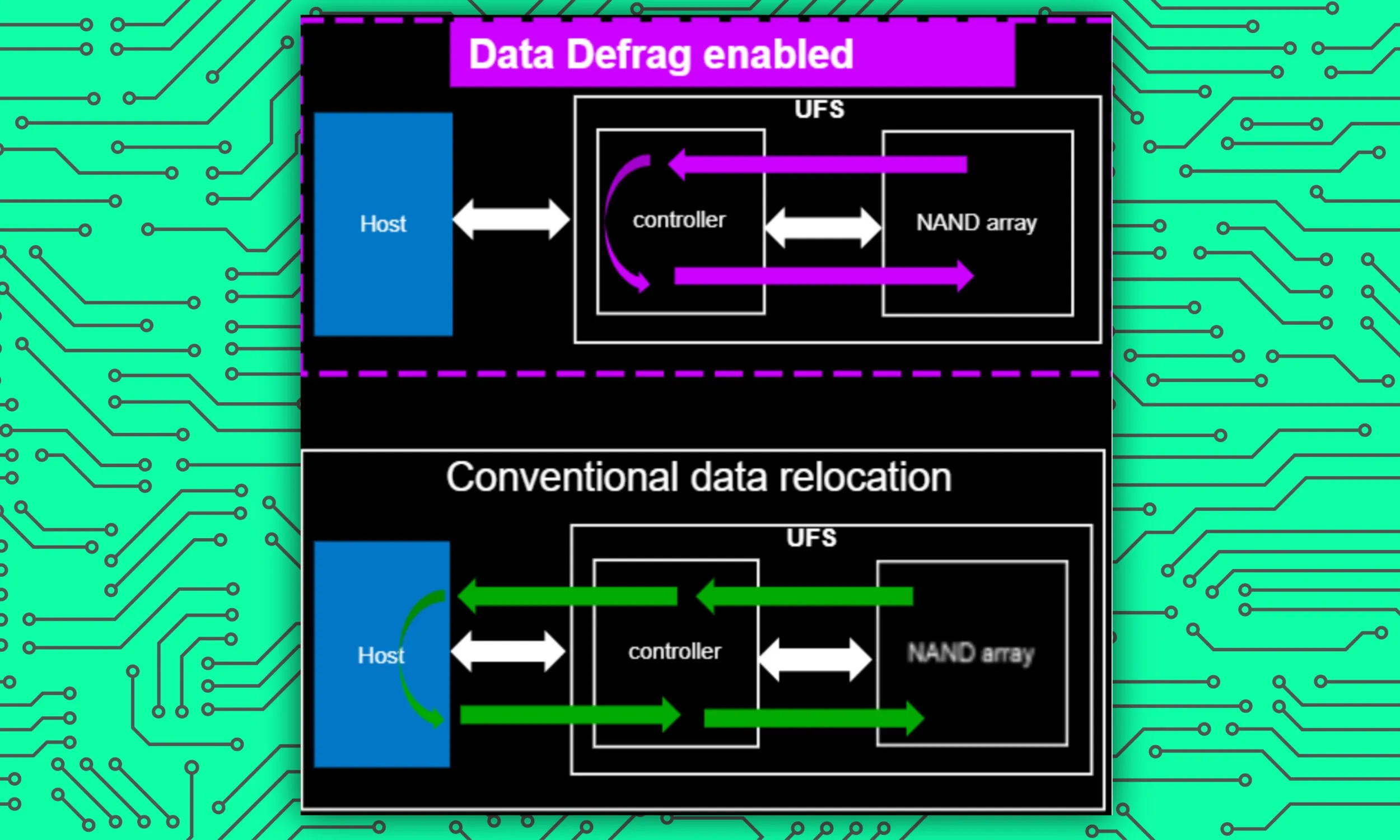
Nel contesto degli smartphone, sebbene una grande quantità di dati venga memorizzata per un lungo periodo di utilizzo, in genere avviene in modo piuttosto casuale. L'effetto netto è che quando il sistema di bordo deve accedere a un particolare tipo di file, diventa più difficile trovarli tutti, con conseguente rallentamento del funzionamento.
Secondo Rivera, Data Defrag non solo aiuta a organizzare l'archiviazione dei dati, ma modifica anche il modo in cui il dispositivo di archiviazione interagisce con il controller del dispositivo. Quindi, esso Aumenta la velocità di lettura dei dati di un sorprendente 60%, accelerando naturalmente tutti i tipi di interazioni tra utente e dispositivo, comprese le attività di intelligenza artificiale.
"Questa funzionalità può aiutare ad accelerare le funzioni dell'intelligenza artificiale, ad esempio quando un modello di intelligenza artificiale generativa, come quello utilizzato per generare un'immagine da un prompt di testo, viene richiamato dall'archiviazione alla memoria, consentendo una lettura più rapida dei dati dall'archiviazione alla memoria", ha dichiarato un funzionario di Micron a Digital Trends.
Intelligence Latency Tracker è un'altra funzionalità che monitora gli eventi di latenza e i fattori che potrebbero rallentare la normale velocità del telefono. In seguito, aiuta a correggere gli errori e a migliorare le prestazioni del telefono, per garantire che le normali attività, così come quelle gestite dall'intelligenza artificiale, non incontrino rallentamenti.
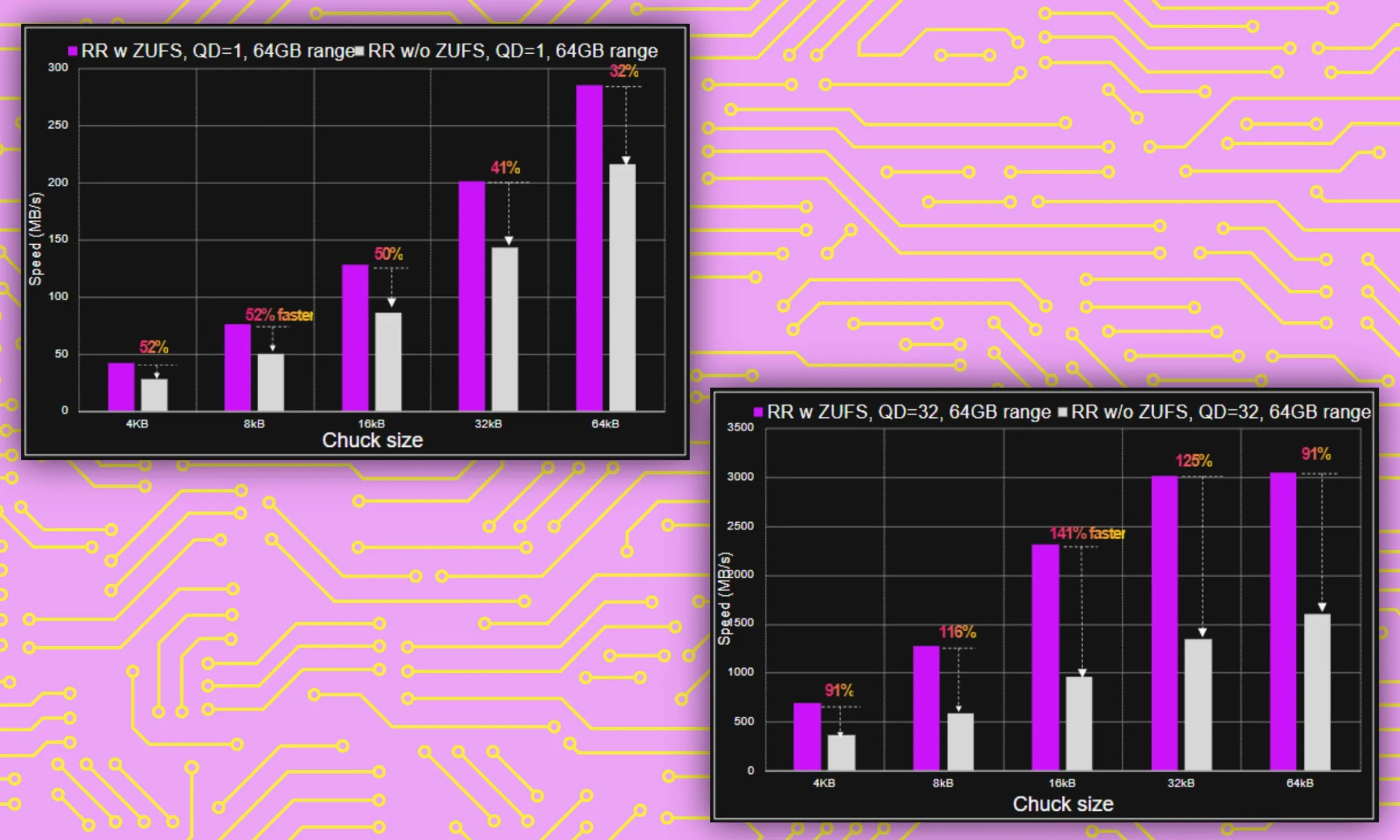
L'ultimo miglioramento dello storage è Zoned UFS. Questo sistema garantisce che i dati di natura input/output simile vengano archiviati in modo organizzato. Questo è molto importante perché consente al sistema di individuare più facilmente i file necessari, evitando di perdere tempo a cercarli tra tutte le cartelle e directory.
"La funzionalità ZUFS di Micron aiuta a organizzare i dati in modo che, quando il sistema deve individuare dati specifici per un'attività, il processo sia più rapido e fluido", ci ha spiegato Rivera.
sovraccarico di RAM
Per quanto riguarda i flussi di lavoro basati sull'intelligenza artificiale, è necessaria una certa quantità di RAM. Maggiore è la capacità, meglio è. Mentre Apple ha fissato la base a 8 GB per la sua suite Apple Intelligence, gli operatori dell'ecosistema Android sono passati a 12 GB come impostazione predefinita di sicurezza. Perché?
"Le esperienze di intelligenza artificiale richiedono un elevato consumo di dati e di energia", spiega Rivera. “Quindi, per mantenere la promessa dell'intelligenza artificiale, la memoria e lo storage devono garantire bassa latenza ed elevate prestazioni con la massima efficienza energetica.”
Con la sua soluzione DRAM LPDDR5X 1γ (1-gamma) di nuova generazione per smartphone, Micron è riuscita a ridurre la tensione operativa dei moduli di memoria. Poi c'è la questione fondamentale delle prestazioni locali. Rivera afferma che i nuovi moduli di memoria possono funzionare a velocità fino a 9.6 gigabit al secondo, garantendo prestazioni di intelligenza artificiale eccezionali.
Micron afferma che i miglioramenti apportati al suo processo di litografia nell'ultravioletto estremo (EUV) hanno aperto la strada non solo a velocità più elevate, ma anche a un salutare aumento del 20% nell'efficienza energetica.
La strada verso esperienze di intelligenza artificiale più personalizzate?
Le soluzioni RAM e di storage di nuova generazione di Micron per smartphone puntano non solo a migliorare le prestazioni dell'intelligenza artificiale, ma anche ad accelerare in generale le attività quotidiane svolte con lo smartphone. Mi chiedevo se la memoria NAND mobile UFS 9 migliorata del G4.1 e la RAM LPDDR1X da 1γ (5-gamma) avrebbero accelerato anche i processori AI offline.
Sia i produttori di smartphone che i laboratori di intelligenza artificiale si stanno orientando sempre più verso l'elaborazione locale dei dati AI. Ciò significa che, anziché inviare le tue query a un server cloud dove il processo viene elaborato e poi il risultato viene inviato al tuo telefono tramite una connessione Internet, l'intero flusso di lavoro viene eseguito localmente sul tuo telefono.

Dalla trascrizione di chiamate e note vocali all'elaborazione di complessi materiali di ricerca in PDF, tutto avviene sul tuo telefono e nessun dato personale lascia mai il tuo dispositivo. È un approccio più sicuro e veloce, ma allo stesso tempo richiede potenti risorse di sistema. Uno di questi requisiti essenziali è un modulo di memoria più veloce ed efficiente.
Le soluzioni di nuova generazione di Micron possono aiutare ad affrontare l'intelligenza artificiale a livello locale? Lei può. Infatti, velocizzerà anche i processi che richiedono una connessione al cloud, come la creazione di video utilizzando il modello Veo di Google, che necessita comunque di potenti server di elaborazione.
"Un'applicazione di intelligenza artificiale nativa eseguita direttamente sul dispositivo avrà la maggior parte del traffico perché non solo legge i dati dell'utente dal dispositivo di archiviazione, ma esegue anche l'inferenza di intelligenza artificiale sul dispositivo", afferma Rivera. "In questo caso, le nostre funzionalità aiuteranno a ottimizzare il flusso di dati per entrambi."
Quindi, quando possiamo aspettarci che i telefoni dotati delle ultime soluzioni Micron arrivino sul mercato? Rivera afferma che tutti i principali produttori di smartphone adotteranno i moduli RAM e di archiviazione di nuova generazione di Micron. Per quanto riguarda l'accesso al mercato, dovresti prendere in considerazione i "principali modelli il cui lancio è previsto per la fine del 2025 o l'inizio del 2026".
I commenti sono chiusi.