

Spiegazione: in che modo la regolarizzazione L1 seleziona automaticamente le feature?
Comprendere il processo di selezione automatica delle funzionalità eseguito dalla regolarizzazione L1 (LASSO).
La selezione delle caratteristiche è il processo di selezione di un sottoinsieme ottimale di caratteristiche da un dato insieme di caratteristiche; il sottoinsieme ottimale è quello che massimizza le prestazioni del modello nell'attività data.
L'identificazione delle caratteristiche può essere un processo manuale o piuttosto esplicito quando eseguito utilizzando metodi di filtro o metodi wrapperIn questi metodi, le feature vengono aggiunte o rimosse iterativamente in base al valore di una metrica fissa, che ne determina l'importanza nel formulare una previsione. Le metriche possono essere l'acquisizione di informazioni, la varianza o una statistica del chi-quadrato, e l'algoritmo deciderà se accettare o rifiutare la feature in base a una soglia fissa sulla metrica. È importante notare che questi metodi non fanno parte della fase di addestramento del modello e vengono eseguiti prima di essa.
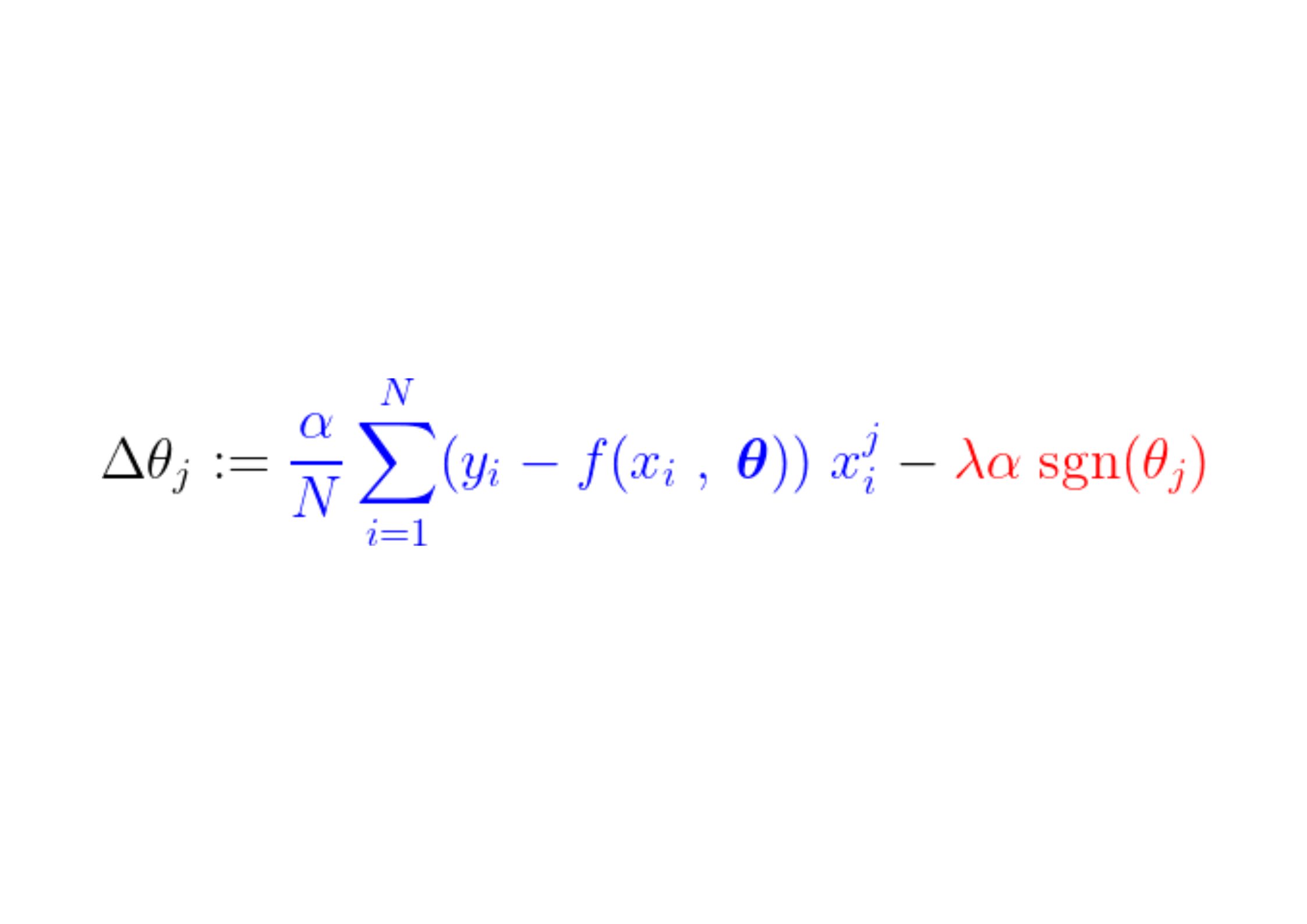
alzarsi Metodi incorporati Identificando implicitamente le feature, senza utilizzare criteri di selezione predefiniti, ed estraendole dai dati di training stessi, questo processo di identificazione delle feature fondamentali fa parte della fase di training del modello. Il modello impara a identificare le feature e a fare previsioni pertinenti simultaneamente. Nelle sezioni seguenti, descriveremo il ruolo della regolarizzazione in questo processo di identificazione delle feature fondamentali, concentrandoci sulla regolarizzazione L1 e sul suo ruolo nel miglioramento dei modelli di machine learning.
Normalizzazione e complessità del modello: strategie avanzate per migliorare le prestazioni
La regolarizzazione è il processo di penalizzazione della complessità del modello per evitare l'overfitting e ottenere la generalizzazione al compito.
In questo caso, la complessità del modello è analoga alla sua capacità di adattarsi agli schemi presenti nei dati di addestramento. Supponendo un semplice modello polinomiale in 'x'fino a un certo punto'd'Più alto è il punteggio'dPer i polinomi, il modello ha una maggiore flessibilità nel catturare pattern nei dati osservati. Questa maggiore flessibilità può portare il modello a memorizzare i dati di training anziché apprendere i pattern reali, il che riduce la sua capacità di generalizzazione a nuovi dati.
Sovraadattamento e sottoadattamento
Quando si cerca di adattare un modello polinomiale con grado d = 2 Su un insieme di campioni di addestramento estratti da un polinomio di terzo ordine con un po' di rumore, il modello non sarà in grado di catturare adeguatamente la distribuzione campionaria. Il modello semplicemente non ha Flessibilità O complessità Necessario per modellare i dati generati da polinomi di grado 3 (o superiore). Questo modello è detto essere sottodimensionato Sui dati di training. Il sottocarico indica che il modello è troppo semplice e non riesce a catturare i pattern sottostanti nei dati.
Lavorando con lo stesso esempio, ora supponiamo di avere un modello con un grado di d = 6Ora, con l'aumentare della complessità, dovrebbe essere facile per il modello stimare il polinomio cubico originale utilizzato per generare i dati (ad esempio, impostando a 3 i coefficienti di tutti i termini con esponenti > 0). Se il processo di addestramento non viene terminato tempestivamente, il modello continuerà a utilizzare la sua flessibilità aggiuntiva per ridurre ulteriormente l'errore e iniziare a catturare anche i campioni rumorosi. Ciò ridurrà significativamente l'errore di addestramento, ma il modello ora... sovradimensionamenti Sui dati di training. Il rumore cambierà in contesti reali (o durante i test) e qualsiasi conoscenza basata sulle previsioni sarà compromessa, con conseguente elevato errore di test. Il sovraccarico significa che il modello è troppo complesso e impara dal rumore anziché dal segnale reale.
Come determinare la complessità ottimale del modello?
In contesti pratici, spesso abbiamo una comprensione limitata o nulla del processo di generazione dei dati o della loro reale distribuzione. Trovare il modello ottimale con la complessità appropriata, in modo che non si sovrapponga o non si adatti, è una sfida significativa. Ciò richiede l'utilizzo di metodi efficaci per valutare le prestazioni del modello e determinare la complessità appropriata che consenta di raggiungere il miglior equilibrio tra accuratezza e generalità. Utilizzando metriche di valutazione e tecniche appropriate come la convalida incrociata, i professionisti possono identificare il modello che offre le migliori prestazioni su dati non visibili, evitando così problemi di sovraadattamento o sottoadattamento.
Una possibile tecnica è quella di partire da un modello sufficientemente robusto e poi ridurne la complessità selezionando le caratteristiche. Minore è il numero di caratteristiche, minore è la complessità del modello.
Come discusso nella sezione precedente, la selezione delle feature può essere esplicita (metodi di filtraggio, metodi di convoluzione) o implicita. Le feature ridondanti che non sono critiche per determinare il valore della variabile target devono essere eliminate per impedire al modello di apprendere pattern non correlati. Anche la regolarizzazione svolge un compito simile. Quindi, in che modo la regolarizzazione e la selezione delle feature si relazionano al raggiungimento di un obiettivo comune di complessità ottimale del modello? Ridurre la complessità nei modelli di apprendimento automatico è fondamentale per migliorare le prestazioni ed evitare l'overfitting, che è ciò su cui si concentrano sia la regolarizzazione che la selezione delle feature.
Regolarizzazione L1 come determinante delle caratteristiche
Continuando con il nostro modello polinomiale, lo rappresentiamo come una funzione f, con input xe transazioni θ e laurea d،
![]()
Per un modello polinomiale, ogni potenza dell'input può essere considerata x_i Come vantaggio, per formare un vettore della seguente forma:
![]()
Definiamo anche una funzione obiettivo, la cui minimizzazione porta ai parametri ottimali. θ* Il termine comprende: regolarizzazione (Regolamento) che penalizza la complessità del modello.
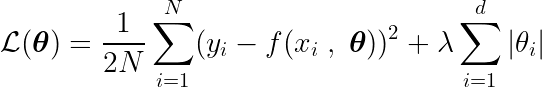
Per trovare il minimo di questa funzione, dobbiamo analizzare tutti i punti critici, cioè i punti in cui la derivata è zero o indefinita.
La derivata parziale può essere scritta rispetto a uno dei parametri, θj, Come segue:
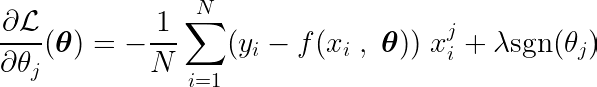
dove la funzione è definita segno Come segue:
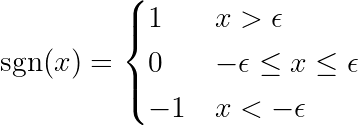
ملاحظةLa derivata di una funzione assoluta è diversa dalla funzione segno (sgn) definita sopra. La derivata originale è indefinita in x = 0. Estendiamo la definizione per rimuovere il punto di flesso in x = 0 e rendere la funzione differenziabile in tutto il suo intervallo. Inoltre, i framework di apprendimento automatico (ML) utilizzano queste funzioni estese quando i calcoli sottostanti coinvolgono la funzione assoluta. Scopri di più. collegamento Nel forum PyTorch.
Calcolando la derivata parziale della funzione obiettivo rispetto ad un singolo coefficiente θj, e uguagliandolo a zero, possiamo costruire un'equazione che collega il valore ottimale di θj Con previsioni, obiettivi e caratteristiche.
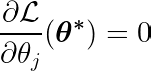
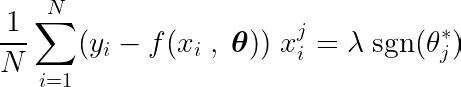
Esaminiamo l'equazione precedente. Se assumiamo che gli input e gli obiettivi siano centrati attorno alla media (ovvero che i dati siano stati standardizzati nella fase di pre-elaborazione), allora il termine sul lato sinistro (LHS) rappresenta effettivamente varianza Tra il numero di caratteristica j e la differenza tra i valori previsti e quelli target.
La covarianza statistica tra due variabili determina l'entità dell'influenza di una variabile sul valore della seconda variabile (e viceversa).
La funzione segno sul lato destro forza la varianza sul lato sinistro ad assumere solo tre valori (poiché la funzione segno restituisce solo -1, 0 e 1). Se la caratteristica j Non necessario e non influisce sulle previsioni, la varianza sarà vicina allo zero, rendendo il coefficiente corrispondente θj* Zero. Ciò comporta la rimozione della feature dal modello. Questo processo contribuisce a ridurre la complessità e a migliorare le prestazioni del modello.
Si pensi alla funzione segnale come a un canyon scavato dall'acqua. Si può camminare lungo il canyon (ovvero il letto del fiume), ma per uscirne si incontrano enormi barriere o pendii ripidi. La regolarizzazione L1 crea un effetto "soglia" simile al gradiente della funzione di perdita. Il gradiente deve essere sufficientemente forte da superare le barriere o diventare nullo, determinando infine l'azzeramento del valore del parametro.
Per fornire un esempio più realistico, si consideri un set di dati contenente campioni derivati da una linea retta (modello a due parametri) con un po' di rumore aggiunto. Un modello ottimale non dovrebbe avere più di due parametri, altrimenti si adatterà al rumore presente nei dati (con l'aggiunta della libertà/potenza del polinomio). La modifica dei parametri di potenza più elevata in un modello polinomiale non influisce sulla differenza tra i target e le previsioni del modello, riducendone quindi la varianza rispetto alla feature.
Durante il processo di addestramento, un passo fisso viene aggiunto/sottratto al gradiente della funzione di perdita. Se il gradiente della funzione di perdita (MSE – errore quadratico medio) è inferiore al passo fisso, il coefficiente alla fine raggiungerà 0. Si noti l'equazione seguente, che illustra come i coefficienti vengono aggiornati utilizzando la discesa del gradiente:

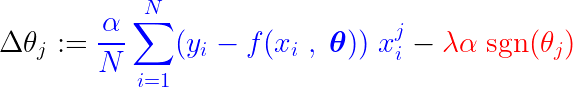
Se la parte blu sopra è più piccola di la, che è un numero molto piccolo di per sé, allora Δθj È un passo quasi costante. laIl segnale per questo passaggio (parte rossa) dipende da: segno(θj), il cui output dipende da θjSe il valore è θj Positivo, cioè maggiore di ε, il segno(θj) è uguale a 1, rendendo così Δθj Circa uguale a -la, spingendolo verso lo zero.
Per sopprimere un passo costante (parte rossa) che azzeri il parametro, il gradiente della funzione di perdita (parte blu) deve essere maggiore della dimensione del passo. Per ottenere un gradiente maggiore della funzione di perdita, il valore della caratteristica deve influenzare significativamente l'output del modello.
In questo modo la caratteristica, o più precisamente il suo parametro corrispondente, il cui valore non è correlato all'output del modello, viene azzerata dalla regolarizzazione L1 durante l'addestramento.
Ulteriori letture e conclusione
- Per avere maggiori informazioni su questo argomento, ho pubblicato una domanda su reddit r/MachineLearning eAzione supplementare Contiene diverse interpretazioni che potresti voler leggere.
- Madiyar Aitbayev ha anche blog interessante Riguarda la stessa domanda, ma con una spiegazione ingegneristica.
- Blog Brian King spiega l'organizzazione da una prospettiva probabilistica.
- questo Discussione Sul sito web CrossValidated spiega perché il criterio L1 incoraggia modelli sparsi. Blog Un articolo dettagliato di Mukul Ranjan spiega perché la norma L1 incoraggia le transazioni a diventare zero, mentre la norma L2 no.
"La regolarizzazione L1 seleziona le feature" è una semplice affermazione con cui la maggior parte degli studenti di ML concorda, senza però approfondire il suo funzionamento interno. Questo blog è un tentativo di presentare ai lettori la mia comprensione e il mio modello mentale per rispondere alla domanda in modo intuitivo. Per suggerimenti e dubbi, potete trovare la mia email a Il mio sito webContinuate a imparare e vi auguro una splendida giornata!
I commenti sono chiusi.