

Perché la maggior parte dei modelli di rischio per la sicurezza informatica falliscono prima di iniziare
La necessità di una riflessione quantitativa sui rischi per la sicurezza informatica
I responsabili della sicurezza informatica si trovano ad affrontare domande impossibili: "Qual è la probabilità che si verifichi una violazione della sicurezza quest'anno?", "Quanto costerà?" e "Quanto dovremmo spendere per fermarla?".
Tuttavia, la maggior parte dei modelli di rischio utilizzati oggi si basa ancora su supposizioni, istinto e mappe di rischio codificate a colori, non sui dati.
Infatti, ho trovato Studio PwC Global Digital Trust Insights 2025 Solo il 15% delle organizzazioni utilizza in modo significativo la modellazione quantitativa del rischio.
Questo articolo analizza i motivi per cui i modelli tradizionali di rischio per la sicurezza informatica risultano insufficienti e come l'applicazione di alcuni strumenti statistici leggeri, come la modellazione probabilistica, offra una soluzione migliore.

Due principali scuole di pensiero nella modellazione del rischio informatico
I modelli di rischio informatico sono: Quadri o metodi sistematici utilizzati per analizzare, valutare e misurare le minacce alla sicurezza informatica e il loro potenziale impatto sui sistemi informativi, sui dati o sulle aziende.
Durante il processo di valutazione del rischio, i professionisti della sicurezza informatica utilizzano principalmente due diversi metodi di modellazione del rischio: qualitativo e quantitativo. Modellazione quantitativa dei rischi informatici Una tecnica avanzata che richiede competenze specialistiche.
Modelli qualitativi per la valutazione del rischio
Immaginate due team che valutano lo stesso rischio. Un team valuta il rischio 4/5 per la probabilità e 5/5 per l'impatto. L'altro team lo valuta 3/5 e 4/5. Entrambi i team tracciano la propria posizione su una matrice. Ma nessuno dei due è in grado di rispondere alla domanda del CFO: "Qual è la probabilità che ciò accada realmente e quanto ci costerà?"
L'approccio qualitativo si basa sulla valutazione soggettiva del rischio, basata principalmente sull'intuizione del valutatore. L'approccio qualitativo generalmente si traduce in una valutazione della probabilità e dell'impatto dei rischi su una scala ordinale, ad esempio da 1 a 5.
Successivamente, i rischi vengono posizionati nella matrice dei rischi per capire dove si collocano su questa scala ordinale.
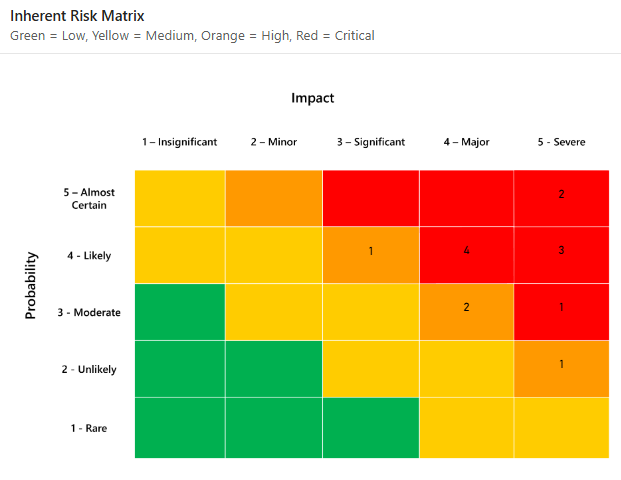
Le due scale ordinali vengono spesso moltiplicate tra loro per aiutare a stabilire la priorità dei rischi più significativi in base alla probabilità e all'impatto. A prima vista, questo sembra ragionevole, poiché la definizione di rischio comunemente utilizzata nella sicurezza informatica è:
[text{Rischio} = text{Probabilità} volte text{Impatto}]
Tuttavia, da un punto di vista statistico, la modellazione qualitativa del rischio comporta alcuni rischi molto significativi.
Il primo di questi rischi è l'uso di scale ordinali. Sebbene l'assegnazione di numeri a scale ordinali dia l'impressione di un supporto matematico al modello, questa è solo un'illusione.
Le scale ordinali sono semplicemente etichette: non esiste una distanza definita tra loro. La distanza tra un rischio con un impatto di "2" e un impatto di "3" non è quantificabile. Cambiare le etichette sulla scala ordinale in "A", "B", "C", "D" ed "E" non fa alcuna differenza.
Ciò, a sua volta, significa che la nostra formula del rischio è errata quando si utilizza la modellazione qualitativa. È impossibile calcolare la probabilità di "B" moltiplicata per l'impatto di "C".
Un'altra grave insidia è la modellazione dell'incertezza. Quando modelliamo il rischio informatico, stiamo modellando eventi futuri incerti. In realtà, i possibili esiti sono molteplici.
Distillare il rischio informatico in stime puntuali (come “20/25” o “Alto”) non coglie l’importante distinzione tra “la perdita annuale più probabile è di 1 milione di dollari” e “c’è una probabilità del 5% di una perdita di 10 milioni di dollari o più”.
Modellazione quantitativa del rischio: analisi avanzata
Immaginate un team che esegue una valutazione del rischio. Stimano un intervallo di risultati, da 100 a 10 milioni di dollari. Eseguendo una simulazione Monte Carlo, ricavano una probabilità del 10% di superare 480 milione di dollari di perdite annuali e una perdita prevista di XNUMX dollari. Ora, quando il CFO chiede: "Quanto è probabile che ciò accada e quanto costerà?"Il team può rispondere con i dati, non solo con l'intuizione.
Questo approccio sposta la conversazione dalle vaghe classificazioni del rischio a Possibilità e potenziale impatto finanziario, un linguaggio che i dirigenti capiscono.
Se hai una formazione in statistica, c'è un concetto in particolare che dovrebbe risaltare:
Probabilità.
La modellazione del rischio informatico è, in sostanza, un tentativo di quantificare la probabilità che si verifichino determinati eventi e il loro impatto. Questo apre le porte a una varietà di strumenti statistici, come la simulazione Monte Carlo, che possono modellare l'incertezza in modo molto più efficace rispetto alle scale ordinali.
La modellazione quantitativa del rischio utilizza modelli statistici per assegnare valori in dollari alle perdite e modellare la probabilità che si verifichino tali eventi di perdita, catturando l'incertezza futura.
Sebbene l'analisi qualitativa possa talvolta approssimare il risultato più probabile, non riesce a cogliere l'intera gamma di incertezza, come eventi rari ma di impatto, noti come "rischio di coda lunga".
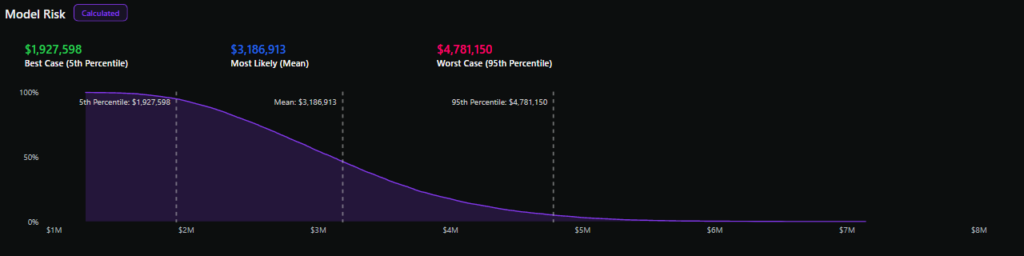
La curva di superamento delle perdite traccia la probabilità di superare un dato importo di perdita annuale sull'asse y e diversi importi di perdita sull'asse x, dando origine a una linea inclinata verso il basso.
Estraendo diverse percentuali dalla curva di eccesso di perdita, come il 90° percentile, la mediana e il XNUMX° percentile, è possibile farsi un'idea delle potenziali perdite annuali per un rischio con un grado di confidenza del XNUMX%.
Mentre una stima puntuale dell'analisi qualitativa può approssimare i rischi più probabili (a seconda dell'accuratezza del giudizio dei valutatori), l'analisi quantitativa cattura l'incertezza nei risultati, anche quelli rari ma comunque possibili (noti come "rischio a coda lunga").
Guardare oltre il rischio informatico: migliorare i modelli di rischio nella sicurezza informatica
Per migliorare i nostri modelli di rischio nella sicurezza informatica, dobbiamo guardare oltre, in particolare alle tecniche utilizzate in altri campi. I modelli di rischio si sono evoluti in modo significativo in una varietà di applicazioni, come la finanza, le assicurazioni, la sicurezza aerea e la gestione della supply chain. Questi ambiti forniscono spunti preziosi che possono essere applicati alla sicurezza informatica.
I team finanziari utilizzano modelli per gestire il rischio del portafoglio di investimenti utilizzando statistiche bayesiane simili. I team assicurativi modellano il rischio utilizzando sofisticati modelli attuariali. Il settore aeronautico modella il rischio di guasto del sistema utilizzando modelli probabilistici. I team di gestione della supply chain modellano il rischio utilizzando simulazioni probabilistiche. Queste metodologie forniscono una solida base per lo sviluppo di modelli efficaci per il rischio informatico.
Gli strumenti esistono già. I fondamenti matematici sono ben compresi. Altri settori hanno aperto la strada. Ora è il momento che la sicurezza informatica adotti modelli quantitativi di rischio per prendere decisioni migliori e più consapevoli, migliorare le strategie di sicurezza informatica e ridurre le potenziali perdite. L'adozione di questi modelli quantitativi rappresenta un passo cruciale verso una gestione più efficace del rischio informatico.
Conclusione principale
| Al-Nihili Al-Nihili | Al-Kumili |
| Scale ordinali (1-5) | Modellazione probabilistica |
| intuizione personale | accuratezza statistica |
| Punti di valutazione singoli | Distribuzioni del rischio |
| Mappe di calore e codici colore | Curve di superamento delle perdite |
| Ignora eventi rari ma gravi | Cattura il rischio a lunga coda |
I commenti sono chiusi.