

Valutazione delle prestazioni dei modelli distillati DeepSeek-R1 su GPQA utilizzando Ollama e valutazioni semplici da OpenAI
Impostare ed eseguire il benchmark GPQA-Diamond sui modelli DeepSeek-R1 distillati localmente per valutarne le capacità di inferenza.
Lancio dell'ultimo modello DeepSeek-R1 Ha avuto grande riscontro nella comunità mondiale dell'intelligenza artificiale. Ha raggiunto risultati rivoluzionari paragonabili ai modelli di inferenza di Meta e OpenAI, e lo ha fatto in una frazione del tempo e a un costo molto più basso.
Ma al di là dei titoli e del clamore online, come possiamo valutare le capacità inferenziali di un modello utilizzando criteri riconosciuti? Questa è una domanda importante per gli esperti di intelligenza artificiale.
. Interfaccia utente Ricerca profonda È facile esplorarne le capacità, ma il suo utilizzo a livello di programmazione fornisce informazioni più approfondite e un'integrazione più fluida nelle applicazioni del mondo reale. Comprendere il funzionamento di questi modelli a livello locale consente inoltre un migliore controllo e un accesso offline.

In questo articolo esploreremo come utilizzare Ollama e valutazioni semplici da OpenAI Per valutare le capacità di inferenza dei modelli distillati DeepSeek-R1 basati sul benchmark GPQA-Diamante Famoso. Questo criterio è considerato uno degli strumenti più importanti per la valutazione dei modelli di intelligenza artificiale nel campo del ragionamento logico.
a te Collegamento al repository GitHub In allegato al presente articolo.
(1) Quali sono i modelli di ragionamento?
I modelli di inferenza, come DeepSeek-R1 e i modelli della serie o di OpenAI (ad esempio o1, o3), sono modelli linguistici di grandi dimensioni (LLM) addestrati utilizzando l'apprendimento per rinforzo per eseguire l'inferenza. Questi modelli sono strumenti avanzati nel campo dell'intelligenza artificiale e rappresentano l'apice dell'evoluzione nella capacità delle macchine di pensare in modo logico e risolvere problemi complessi.
Le euristiche sono caratterizzate dalla riflessione profonda prima di rispondere, producendo una lunga serie di pensieri interni prima di rispondere. Eccelle nella risoluzione di problemi complessi, nella programmazione, nel ragionamento scientifico e nella pianificazione in più fasi dei flussi di lavoro degli agenti. Queste capacità li rendono indispensabili in settori quali lo sviluppo software avanzato, la ricerca scientifica e l'automazione di processi complessi.
(2) Che cosa è il modello DeepSeek-R1?
DeepSeek-R1 è un modello di linguaggio di grandi dimensioni (LLM) open source all'avanguardia, progettato specificamente per Ragionamento avanzato. Presentato a gennaio 2025 nel documento di ricerca "DeepSeek-R1: potenziare la potenza di inferenza nei modelli linguistici di grandi dimensioni con l'apprendimento per rinforzo". DeepSeek-R1 è un modello pionieristico nel campo dell'intelligenza artificiale.
Questo modello si basa su un'architettura di modello linguistico di grandi dimensioni (LLM) con 671 miliardi di parametri ed è stato addestrato utilizzando un apprendimento di rinforzo (RL) esteso basato sul seguente percorso:
- Due fasi di potenziamento mirano a scoprire modelli di ragionamento migliorati e ad allinearli alle preferenze umane.
- Due fasi di messa a punto supervisionata servono da base per le capacità di inferenza e non inferenza del modello.
Per illustrare questo, DeepSeek ha addestrato due modelli:
- Il primo modello, DeepSeek-R1-Zero, è un modello di inferenza addestrato utilizzando l'apprendimento per rinforzo e genera dati per addestrare il secondo modello, DeepSeek-R1.
- Ciò viene ottenuto producendo tracce di inferenza, di cui vengono conservati solo gli output di alta qualità in base ai risultati finali.
- Ciò significa che, a differenza della maggior parte dei modelli, gli esempi di apprendimento per rinforzo (RL) in questa pipeline di addestramento non sono curati da esseri umani, ma generati dal modello stesso.
Il risultato è che il modello ha raggiunto prestazioni simili a modelli leader come Modello o1 di OpenAI In compiti quali matematica, programmazione e ragionamento complesso.
(3) Comprensione del processo di distillazione e dei modelli distillati da DeepSeek-R1
Oltre al modello completo, hanno anche reso open source sei modelli densi più piccoli (chiamati anche DeepSeek-R1) di diverse dimensioni (1.5B, 7B, 8B, 14B, 32B, 70B), distillati da DeepSeek-R1 in base a Qwen O Lama Come modello base.
Distillazione Si tratta di una tecnica in cui un modello più piccolo ("studente") viene addestrato a replicare le prestazioni di un modello più grande e potente che è stato precedentemente addestrato ("insegnante").
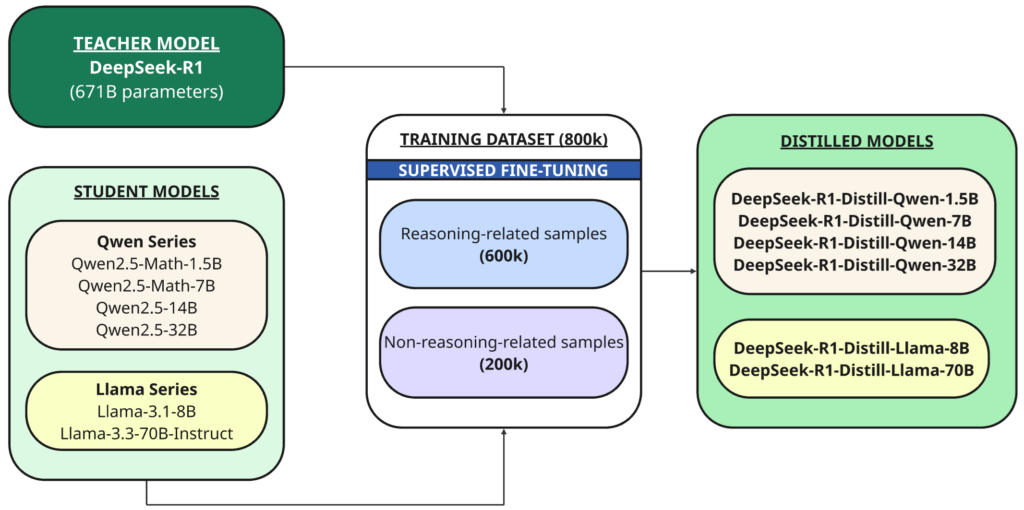
In questo caso, l'insegnante è il modello DeepSeek-R1 671B e gli studenti sono i sei modelli distillati utilizzando questo modello base open source:
- Qwen2.5 — Matematica-1.5B
- Qwen2.5 — Matematica-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lama-3.1 — 8B
- Llama-3.3 — 70B-Istruzione
DeepSeek-R1 è stato utilizzato come modello di insegnamento per generare 800,000 campioni di addestramento, una miscela di campioni di inferenza e non di inferenza, per la distillazione attraverso messa a punto supervisionata Per i modelli base (1.5B, 7B, 8B, 14B, 32B e 70B).
Quindi, perché distilliamo?
L'obiettivo è trasferire le capacità di inferenza di modelli più grandi, come DeepSeek-R1 671B, a modelli più piccoli e più efficienti. Ciò consente ai modelli più piccoli di gestire attività di inferenza complesse, in modo più rapido ed efficiente in termini di risorse.
Inoltre, DeepSeek-R1 ha un numero enorme di parametri (671 miliardi), il che rende difficile il suo funzionamento sulla maggior parte dei dispositivi consumer.
Persino il MacBook Pro più potente, con una memoria unificata massima di 128 GB, non è sufficiente per far funzionare un modello con parametri da 671 miliardi.
Pertanto, i modelli distillati aprono la possibilità di implementarli su dispositivi con risorse di calcolo limitate.
raggiunto Pigrizia Un risultato notevole ottenuto quantizzando il modello originale DeepSeek-R1 da 671 miliardi di parametri a soli 131 GB, ovvero una notevole riduzione delle dimensioni dell'80%. Tuttavia, il requisito di 131 GB di VRAM rimane un ostacolo significativo, soprattutto per gli sviluppatori che lavorano su dispositivi con risorse limitate. Questo risultato rappresenta un passo significativo verso la possibilità di rendere i grandi modelli di intelligenza artificiale accessibili a una più ampia gamma di utenti.
(4) Selezione del modello distillato ottimale
Con sei diverse dimensioni di modelli distillati tra cui scegliere, la scelta del modello giusto dipende in larga misura dalle capacità delle apparecchiature locali.
Per chi ha GPU o CPU ad alte prestazioni e necessita del massimo delle prestazioni, i modelli DeepSeek-R1 più grandi (32B e superiori) sono l'ideale; anche la versione Quantum 671B è valida.
Tuttavia, se le risorse sono limitate o preferisci tempi di costruzione più rapidi (come me), le varianti distillate più piccole, come 8B o 14B, sono un'opzione migliore. In questo modo si bilanciano prestazioni e requisiti di risorse.
Per questo progetto userò il modello distillato DeepSeek-R1. Qwen-14B, che corrisponde alle limitazioni hardware riscontrate. Questo modello (14B) rappresenta un ottimo compromesso tra precisione e velocità, il che lo rende perfetto per il mio ambiente di sviluppo.
(5) Criteri per la valutazione della capacità inferenziale di modelli linguistici di grandi dimensioni
I modelli linguistici di grandi dimensioni (LLM) vengono solitamente valutati utilizzando parametri standardizzati che determinano le loro prestazioni in varie attività, tra cui la comprensione del linguaggio, la generazione di codice, il rispetto delle istruzioni e la risposta alle domande. Esempi comuni includono metriche come: MMLU, E Valutazione umana, E MGSM. Queste metriche sono essenziali per valutare le capacità dei modelli linguistici di grandi dimensioni.
Per misurare la capacità di ragionamento di un modello linguistico di grandi dimensioni, abbiamo bisogno di parametri di riferimento più impegnativi, che si concentrino molto sul ragionamento e vadano oltre i compiti superficiali. Ecco alcuni esempi comuni che si concentrano sulla valutazione delle capacità di ragionamento avanzate:
(i) Esame AIME 2024: Matematica competitiva
- Preparare Esame di matematica su invito americano (AIME) 2024 Un solido benchmark per valutare le capacità dei grandi modelli linguistici (LLM) nel ragionamento matematico.
- Questo esame rappresenta una sfida significativa nella matematica competitiva, poiché presenta problemi complessi e articolati in più fasi. L'esame verifica la capacità dei modelli linguistici di grandi dimensioni di comprendere domande complesse, applicare ragionamenti avanzati ed eseguire manipolazioni simboliche precise. L'AIME è un importante strumento di valutazione delle capacità di risoluzione di problemi matematici complessi.
(ii) Codeforces – Codice della concorrenza
- alzarsi Standard Codeforces Valutazione della capacità di inferenza di un modello linguistico di grandi dimensioni (LLM) utilizzando problemi di programmazione competitiva del mondo reale di Codeforces, una piattaforma nota per le sfide algoritmiche. Codeforces è il gold standard per la valutazione delle capacità dei modelli di intelligenza artificiale di risolvere problemi complessi.
- Questi problemi mettono alla prova la capacità di un modello linguistico di grandi dimensioni (LLM) di comprendere istruzioni complesse, eseguire ragionamenti logici e matematici, pianificare soluzioni in più fasi e generare codice corretto ed efficiente. Questi problemi richiedono una profonda conoscenza degli algoritmi e delle strutture dati, nonché la capacità di tradurre il problema in codice eseguibile.
(iii) GPQA Diamond – Domande scientifiche di livello dottorale
- GPQA-Diamond è un sottoinsieme selezionato di Le domande più difficili Dallo standard GPQA (Risposte alle domande di fisica post-laurea) Il più ampio e specificamente progettato per ampliare i confini della capacità dei modelli LLM di trarre inferenze in argomenti avanzati di livello PhD. Questo standard rappresenta una vera sfida alla capacità dell'intelligenza artificiale di comprendere e dedurre concetti scientifici complessi.
- Mentre il GPQA include una serie di domande post-laurea concettuali e basate su calcoli, il GPQA-Diamond isola solo le domande più impegnative e quelle che richiedono un ragionamento intensivo.
- Questo criterio è considerato "resistente a Google", il che significa che è difficile rispondere anche con un accesso web illimitato. Ciò lo rende uno strumento prezioso per valutare la capacità di grandi modelli linguistici di ragionare in modo indipendente.
- Ecco un esempio di domanda GPQA-Diamond:
### GPQA Diamond - Domanda di esempio (Biologia molecolare) Una cellula eucariotica ha sviluppato un meccanismo per trasformare i mattoni macromolecolari in energia. Il processo avviene nei mitocondri, le fabbriche di energia cellulare. Nella serie di reazioni redox, l'energia proveniente dal cibo viene immagazzinata tra i gruppi fosfato e utilizzata come valuta cellulare universale. Le molecole cariche di energia vengono trasportate fuori dal mitocondrio per essere utilizzate in tutti i processi cellulari. Hai scoperto un nuovo farmaco antidiabete e vuoi verificare se ha effetti sui mitocondri. Hai impostato una serie di esperimenti con la tua linea cellulare HEK293. Quale degli esperimenti elencati di seguito non ti aiuterà a scoprire il ruolo mitocondriale del tuo farmaco: (A) Estrazione mediante centrifugazione differenziale dei mitocondri seguita dal kit di analisi colorimetrica dell'assorbimento del glucosio (B) Citometria a flusso dopo marcatura con 2.5 µM di ioduro di 5,5',6,6'-tetracloro-1,1',3,3'-tetraetilbenzimidazolilcarbocianina (C) Trasformazione delle cellule con luciferasi ricombinante e lettura del luminometro dopo l'aggiunta di 5 µM di luciferina al supernatante (D) Microscopia confocale a fluorescenza dopo colorazione delle cellule con Mito-RTP
In questo progetto, Utilizziamo GPQA-Diamond come standard per la conclusione., come l'ho usato OpenAI e DeepSeek Per valutare i loro modelli di inferenza. La scelta di GPQA-Diamond come criterio di valutazione è prova della sua difficoltà e importanza nel campo dello sviluppo dell'intelligenza artificiale.
(6) Strumenti utilizzati
In questo progetto utilizziamo principalmente Ollama e valutazioni semplici Da OpenAI. Ollama è una potente piattaforma per l'esecuzione locale di modelli linguistici di grandi dimensioni, mentre simple-evals fornisce un framework per valutare le prestazioni di questi modelli.
(i) Ollama
Ollama Si tratta di uno strumento open source che semplifica l'esecuzione di modelli linguistici di grandi dimensioni (LLM) sul nostro computer o su un server locale. Olama è una piattaforma ideale per eseguire modelli di intelligenza artificiale in locale.
Funziona come gestore e runtime, gestendo attività quali download e configurazione dell'ambiente. Ciò consente agli utenti di interagire con questi modelli senza dover disporre di una connessione Internet costante o di affidarsi ai servizi cloud. La gestione di modelli linguistici di grandi dimensioni (LLM) locali è una funzionalità fondamentale di Olama.
Supporta molti grandi modelli di linguaggio open source, tra cui DeepSeek-R1, ed è compatibile con più piattaforme: macOS, Windows e Linux. Inoltre, offre una configurazione semplice con il minimo sforzo e un utilizzo efficiente delle risorse. Ollama ti consente di sfruttare la potenza dell'intelligenza artificiale direttamente sul tuo dispositivo.
ImportanteAssicurati che il tuo computer locale abbia: Accessibilità GPU Per Ollama, questo velocizza notevolmente le prestazioni e rende il benchmarking successivo più efficiente rispetto alla CPU. Esegui il comando
nvidia-smiNel terminale per verificare se la GPU è stata rilevata. Questa procedura garantisce che le capacità del dispositivo siano massimizzate per eseguire i modelli con elevata efficienza.
(ii) Libreria OpenAI simple-evals per la valutazione di modelli linguistici
Preparare valutazioni semplici Una libreria leggera progettata per valutare modelli linguistici utilizzando la metodologia di valutazione zero-shot con prompt basati sulla catena di pensiero. Questa libreria include benchmark di valutazione popolari come MMLU, MATH, GPQA, MGSM e HumanEval e mira a simulare scenari di utilizzo nel mondo reale per valutare le prestazioni dei modelli di intelligenza artificiale in attività di inferenza complesse.
Alcuni di voi potrebbero avere familiarità con la libreria di valutazione più popolare e completa di OpenAI chiamata Valutazioni, che è diverso dalle valutazioni semplici.
Infatti la pagina indica README La specifica simple-evals indica che non è destinata a sostituire la libreria. Valutazioni.
Quindi, perché utilizziamo simple-evals?
La risposta semplice è che valutazioni semplici È dotato di testi di valutazione integrati per gli standard di inferenza a cui miriamo (come GPQA), di cui la libreria è priva. Valutazioni.
Inoltre, non ho trovato altri strumenti o piattaforme, a parte simple-evals, che forniscano un modo diretto e nativo nel linguaggio. Python Per eseguire molti standard importanti, come GPQA, soprattutto quando si lavora con Ollama.
(7) Risultati della valutazione
Come parte della valutazione, ho selezionato: 20 domande casuali Dal set di domande GPQA-Diamond di 198 domande su cui lavorare Modulo 14B Distillatore. Ci sono voluti 216 minuti in totale, ovvero circa 11 minuti a domanda.
Il risultato è stato un po' deludente, in quanto ha registrato 10% Solo che questo risultato è significativamente inferiore a quello riportato del 73.3% per il modello 1B DeepSeek-R671.
Il problema principale che ho notato è che durante il ragionamento interno intensivo, Spesso il modello non riusciva a produrre alcuna risposta (ad esempio, restituendo codici di inferenza come righe finali di output) oppure forniva una risposta che non corrispondeva al formato a scelta multipla previsto (ad esempio, risposta: A).
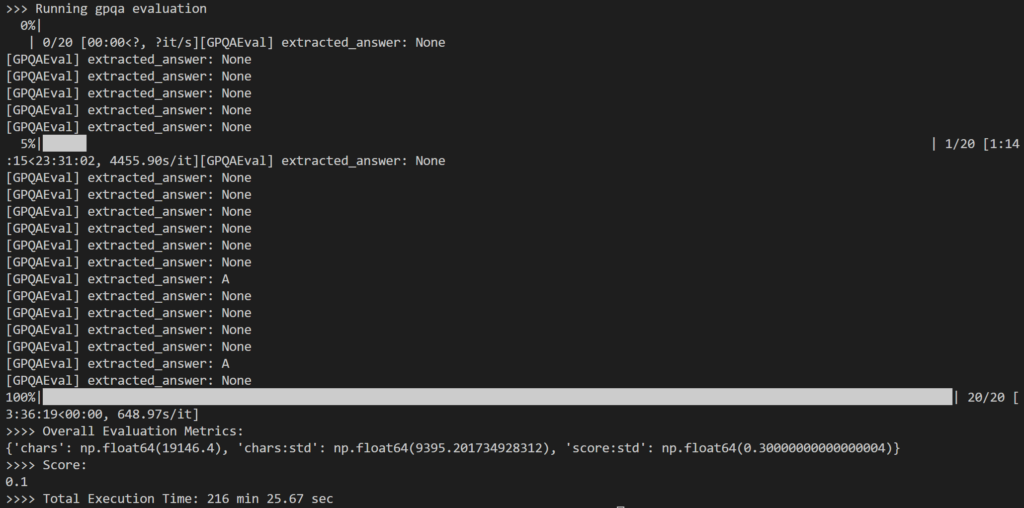
Come mostrato sopra, molti degli output risultavano essere: None Poiché la logica regex in simple-evals non è riuscita a rilevare il modello di risposta previsto nella risposta LLM.
Mentre quello ragionamento simile a quello umano È stato interessante osservarlo, perché mi aspettavo una prestazione migliore in termini di accuratezza nelle risposte alle domande.
Ho anche letto online che alcuni utenti sostengono che anche il modello 32B più grande non funziona bene come l'o1. Ciò ha sollevato dubbi sull'utilità dei modelli di inferenza distillata, soprattutto quando hanno difficoltà a fornire risposte corrette nonostante generino inferenze lunghe.
Tuttavia, GPQA-Diamond è un benchmark molto impegnativo, quindi questi modelli potrebbero comunque essere utili per attività di inferenza più semplici. Anche i minori requisiti di calcolo lo rendono più semplice.
Inoltre, il team di DeepSeek ha consigliato di eseguire più test e di calcolare la media dei risultati come parte del processo di benchmarking, un aspetto che ho trascurato a causa di limiti di tempo.
(8) Guida dettagliata passo dopo passo
Fino a questo punto abbiamo trattato i concetti di base e le conclusioni principali.
Se sei pronto per un'esperienza pratica e tecnica, questa sezione fornisce un'analisi approfondita dei meccanismi interni e dell'implementazione passo dopo passo. Questa pratica guida tecnica ti fornirà una comprensione completa del funzionamento del sistema.
Per visualizzare (o copiare) Repository GitHub complementare Da seguire. I requisiti di configurazione dell'ambiente virtuale sono disponibili qui. qui.
(i) Configurazione iniziale – Ollama
Iniziamo scaricando Ollama. Visita
Pagina di download di Ollama, seleziona il tuo sistema operativo e segui le istruzioni di installazione corrispondenti.
Una volta completata l'installazione, avvia Ollama facendo doppio clic sull'applicazione Ollama (per Windows e macOS) o eseguendo il comando ollama serve Nel terminale.
(ii) Configurazione iniziale – OpenAI simple-evals
La configurazione simple-evals è relativamente unica.
Mentre simple-evals si presenta come una libreria, L'assenza di file __init__.py Nel repository significa che non è strutturato come un pacchetto Python vero e proprio., causando errori di importazione dopo la clonazione del repository in locale. Ciò significa che non si tratta di un pacchetto Python standard nel senso comunemente usato nell'ingegneria del software.
Poiché non è pubblicato su PyPI e non dispone di file di packaging standard come setup.py O pyproject.tomlNon può essere installato tramite pip. Ciò rappresenta una piccola sfida per i nuovi sviluppatori.
Fortunatamente, possiamo usare Sottomoduli Git Come soluzione alternativa diretta. Questi moduli consentono di includere un repository Git all'interno di un altro, semplificando la gestione delle dipendenze.
“`html
Un sottomodulo Git ci consente di includere il contenuto di un altro repository Git all'interno del nostro progetto. Estrae i file da un repository esterno (ad esempio simple-evals), ma ne mantiene separata la cronologia.
È possibile scegliere uno dei due metodi (A o B) per estrarre il contenuto di simple-evals:
(a) Se cloni il repository del mio progetto
Il mio repository di progetti include già simple-evals Come sottomodulo, puoi semplicemente eseguire:
git submodule update --init --recursive(b) Se lo si aggiunge a un progetto appena creato.
Per aggiungere manualmente simple-evals come sottomodulo, eseguire questo:
git submodule add https://github.com/openai/simple-evals.git simple_evalsملاحظة: Quello simple_evals Alla fine (con sottolineare) è molto importante. Specifica il nome della cartella, utilizzando invece un trattino (ad esempio semplice-evals) possono causare problemi di importazione in seguito.
Passaggio finale (per entrambi i metodi)
Dopo aver estratto il contenuto del repository, è necessario creare un file. __init__.py Vuoto nella cartella simple_evals Quello appena creato può essere importato come unità. Puoi crearlo manualmente oppure utilizzare il seguente comando:
touch simple_evals/__init__.py(iii) Estrazione del modello DeepSeek-R1 tramite Ollama
Il passo successivo consiste nello scaricare il modello distillato localmente di tua scelta (ad esempio, 14B) utilizzando questo comando:
Un elenco dei modelli DeepSeek-R1 disponibili è disponibile su Ollama. qui. Per ottenere le migliori prestazioni, si consiglia di utilizzare la versione più recente del modello.
ollama pull deepseek-r1:14b(Quarto) Specificare le impostazioni
Definiamo i parametri nel file YAML delle impostazioni, come mostrato di seguito:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Nome del modello (corrisponde all'elenco dei modelli Ollama) MODEL_TEMPERATURE: 0.6 # Impostato tra 0.5 e 0.7 per DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
La temperatura del modello è impostata su 0.6 (Rispetto al tipico valore predefinito pari a 0). Ciò segue le raccomandazioni d'uso di DeepSeek, che suggeriscono un intervallo di temperatura compreso tra 0.5 e 0.7 (0.6 è il valore consigliato). Per evitare ripetizioni infinite o risultati incoerenti. Questa impostazione è necessaria per migliorare la qualità dell'output e garantirne la coerenza.
Non perdere l'occasione di dare un'occhiata Raccomandazioni d'uso uniche e interessanti di DeepSeek-R1 – in particolare per i benchmark – per garantire prestazioni ottimali quando si utilizzano i modelli DeepSeek-R1.
EVAL_N_EXAMPLES Questo è il parametro utilizzato per impostare il numero di domande dal set completo di 198 domande utilizzate nella valutazione. Questo parametro è necessario per adattare il processo di valutazione in base alle risorse disponibili e agli obiettivi specifici del test.
(v) Impostazione del codice Sampler
Per supportare i modelli linguistici basati su Ollama all'interno del framework simple-evals, creiamo una classe wrapper personalizzata denominata OllamaSampler E tienilo dentro utils/samplers/ollama_sampler.py. Il campionatore è un componente essenziale per testare e valutare le prestazioni dei modelli linguistici.
# utils/samplers/ollama_sampler.py import ollama classe OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
In questo contesto, significa campionatore (Sampfier) Una classe Python che genera output da un modello linguistico in base a un prompt specificato. Questo strumento è fondamentale per garantire che il modello generi risposte diversificate e rappresentative.
Poiché i campionatori in simple-evals coprono solo provider come OpenAI e Claude, abbiamo bisogno di una classe campionatore che fornisca un'interfaccia compatibile con Ollama. Ciò garantisce una perfetta integrazione con il quadro di valutazione.
alzarsi OllamaSampler Estrae una domanda GPQA, la invia al modulo a una temperatura specificata e restituisce una risposta in testo normale. La temperatura è un parametro importante che controlla la casualità dell'output.
Metodo incluso _pack_message Per garantire che il formato di output corrisponda a quanto previsto dagli script di valutazione in simple-evals. Ciò garantisce coerenza e semplicità di analisi.
6. Creare uno script di valutazione
Il codice seguente mostra come impostare l'implementazione della valutazione in un file. main.py, compreso l'uso della categoria GPQAEval Dalla libreria simple-evals per eseguire test di benchmark GPQA.
Funzione run_eval() Si tratta di uno strumento di valutazione configurabile che testa i grandi modelli linguistici (LLM) tramite Ollama rispetto a standard quali GPQA. Questa funzione è necessaria per valutare accuratamente le prestazioni dei modelli.
# main.py def run_eval(): start_time = time.time() # Carica il file di configurazione config = load_config("config/config.yaml") # Inizializza il campionatore Ollama (wrapper per la chat di Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Seleziona la classe di valutazione da utilizzare in base a EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Esecuzione della valutazione di {eval_benchmark}") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Predefinito 1 "num_examples": config["EVAL_N_EXAMPLES"], # Imposta su 20 "variant": config["GPQA_VARIANT"], # Sottoinsieme GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Crea ed esegui l'eval appropriato evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Esegui la valutazione con il campionatore end_time = time.time() elapsed_seconds = end_time - start_time minuti, secondi = divmod(elapsed_seconds, 60) # Calcola il tempo totale impiegato # Il risultato restituito è un EvalResult che include un elenco di SingleEvalResult e metriche aggregate print(">>>> Metriche di valutazione complessive:", results.metrics) print(">>>> Punteggio:", results.score) print(f">>>> Tempo di esecuzione totale: {int(minuti)} min {secondi:.2f} sec") se __name__ == "__main__": # Esegui l'esecuzione della valutazione GPQA run_eval()
La funzione carica le impostazioni dal file di configurazione, imposta la classe di valutazione appropriata da simple-evals ed esegue il modello attraverso un processo di valutazione uniforme. Viene salvato in un file. main.py, che può essere eseguito utilizzando il comando python main.py. Ciò garantisce un processo di valutazione coerente e ripetibile.
Seguendo i passaggi sopra indicati, abbiamo impostato ed eseguito con successo il benchmark GPQA-Diamond sul modello distillato DeepSeek-R1. Questo processo fornisce informazioni preziose sulle capacità del modello.
La linea di fondo
In questo articolo, esploriamo come possiamo combinare strumenti come Ollama e simple-evals di OpenAI per esplorare e valutare modelli distillati da DeepSeek-R1, con un focus su Valutazione delle prestazioni di modelli linguistici di grandi dimensioni.
I modelli distillati potrebbero non corrispondere ancora al modello originale da 671 miliardi di parametri su benchmark di inferenza complessi come GPQA-Diamond. Tuttavia, dimostra come la distillazione possa ampliare l'accesso alle capacità di inferenza dei grandi modelli linguistici (LLM). Migliorare l'accesso a modelli linguistici di grandi dimensioni Si tratta di un obiettivo importante in questo ambito.
Nonostante le prestazioni inferiori nelle attività complesse di livello PhD, queste varianti più piccole potrebbero comunque essere applicabili in scenari meno impegnativi, aprendo la strada a un'implementazione locale efficiente su una gamma più ampia di dispositivi. Ciò contribuisce a Distribuisci modelli linguistici di grandi dimensioni a livello locale In modo efficiente.
I commenti sono chiusi.