

Raggiungere la certezza nei modelli linguistici di grandi dimensioni (LLM) utilizzando circuiti decisionali intelligenti
L'incertezza non è una novità nella tecnologia: tutti i sistemi moderni superano input e output incerti utilizzando strutture di controllo matematicamente comprovate.
La promessa degli agenti AI ha conquistato il mondo. Gli agenti possono interagire con il mondo che li circonda, scrivere articoli (ma non questo), intraprendere azioni per tuo conto e, in generale, rendere semplice e accessibile la parte difficile dell'automazione di qualsiasi attività.
Gli agenti prendono di mira le parti più difficili delle operazioni e risolvono rapidamente i problemi. A volte troppo in fretta: se il processo basato su agenti richiede che un essere umano intervenga per decidere il risultato, la fase di revisione umana può diventare un collo di bottiglia nel processo.
Un esempio di processo basato su agenti è l'elaborazione e la classificazione delle telefonate dei clienti. Anche un agente con una precisione del 99.95% commetterà 5 errori nell'ascoltare 10,000 chiamate. Nonostante lo sappia, l'agente non può dirtelo. Quale 5 chiamate su 10,000 sono state classificate in modo errato.

La tecnica "LLM-as-a-Judge" è una tecnica in cui ogni input viene inserito in un altro processo LLM per valutare se l'output derivante dall'input è corretto. Tuttavia, poiché si tratta di un altro processo LLM, potrebbe anche essere impreciso. Queste due operazioni probabilistiche creano una matrice di confusione con veri positivi, falsi negativi, veri negativi e falsi positivi.
In altre parole, una voce correttamente classificata da un processo LLM potrebbe essere giudicata errata dal suo giudice LLM o viceversa.
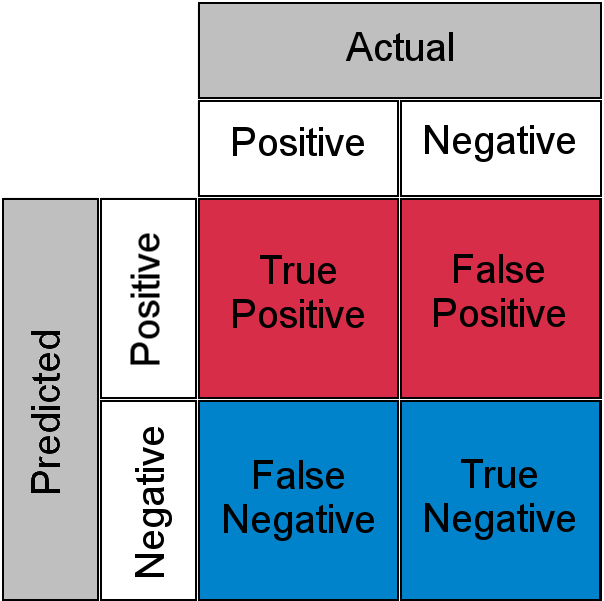
A causa di ciò " L'ignoto conosciuto "Per un carico di lavoro delicato, un essere umano deve esaminare e comprendere tutte le 10,000 chiamate. Ci troviamo di nuovo di fronte allo stesso problema di collo di bottiglia.
Come possiamo aumentare la certezza statistica nei nostri processi basati su agenti? In questo post, realizzo un sistema che ci consente di essere più certi nei nostri processi basati su agenti, lo generalizzo a un numero arbitrario di agenti e sviluppo una funzione di costo per orientare i futuri investimenti nel sistema. Il codice che utilizzo in questo post è disponibile nel mio repository. circuiti decisionali AI.
Circuiti decisionali AI
Rilevare e correggere gli errori non sono concetti nuovi. La correzione degli errori è fondamentale in settori come l'elettronica digitale e analogica. Anche i progressi nell'informatica quantistica dipendono dall'ampliamento delle capacità di correzione e rilevamento degli errori. Possiamo prendere spunto da questi sistemi e implementare qualcosa di simile con gli agenti di intelligenza artificiale. Ad esempio, puoi Algoritmi di intelligenza artificiale Utilizzo avanzato delle tecniche di correzione degli errori presenti nei sistemi di comunicazione.
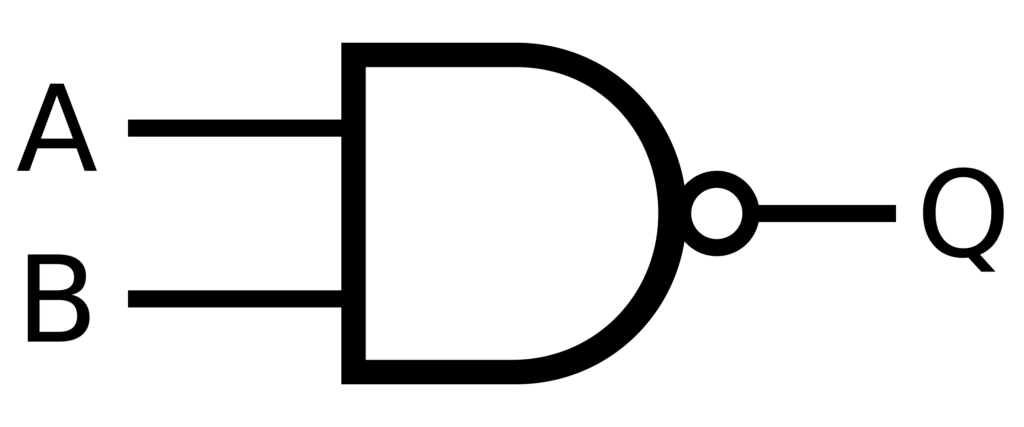
Nella logica booleana, le porte NAND rappresentano il Santo Graal dell'informatica perché possono eseguire qualsiasi operazione. È funzionalmente completo, il che significa che qualsiasi operazione logica può essere creata utilizzando solo porte NAND. Questo principio può essere applicato ai sistemi di intelligenza artificiale per creare strutture decisionali solide con correzione degli errori integrata. Ciò consente la creazione di reti neurali Più affidabile e in grado di gestire dati incompleti o rumorosi.
Dai circuiti elettronici ai circuiti decisionali intelligenti (IA)
Proprio come i circuiti elettronici utilizzano la ripetizione e la verifica per garantire calcoli affidabili, i circuiti decisionali intelligenti (IA) possono utilizzare più agenti con prospettive diverse per arrivare a risultati più accurati. Questi circuiti possono essere realizzati utilizzando i principi della teoria dell'informazione e della logica booleana:
- Elaborazione ridondante: Più agenti di intelligenza artificiale elaborano gli stessi input in modo indipendente, in modo simile a come le moderne CPU utilizzano circuiti ridondanti per rilevare errori hardware. Questo processo aumenta l'affidabilità del sistema di intelligenza artificiale.
- Meccanismi di consenso: I risultati delle decisioni vengono combinati utilizzando sistemi di voto o medie ponderate, simili alle porte logiche di maggioranza nell'elettronica a prova di guasti. Questi meccanismi garantiscono che la decisione finale rifletta il consenso tra gli agenti.
- Agenti di validazione: Gli auditor specializzati in intelligenza artificiale verificano la ragionevolezza dell'output, lavorando in modo simile ai codici di rilevamento degli errori come Bit di parità O controlli di ridondanza ciclici (controlli CRC). Questi agenti riducono la probabilità di prendere decisioni sbagliate.
- Integrazione umana nel ciclo: Verifica umana strategica nei punti chiave del processo decisionale, in modo simile a come i sistemi biometrici utilizzano la supervisione umana come livello di verifica finale. Ciò garantisce che le decisioni importanti siano soggette alla valutazione umana.
Fondamenti matematici dei circuiti decisionali nell'intelligenza artificiale
L'affidabilità di questi sistemi può essere determinata quantitativamente utilizzando la teoria della probabilità.
Da un lato, la probabilità di fallimento deriva dall'accuratezza osservata nel tempo attraverso un set di dati di prova, memorizzato in un sistema come LangSmith.

Per un fattore di precisione del 90%, la probabilità di fallimento, p_1، 1–0.9 È 0.1, ovvero il 10%.

La probabilità che due fattori indipendenti non riescano a rispondere allo stesso input è la probabilità che entrambi i fattori siano accurati moltiplicata tra loro:
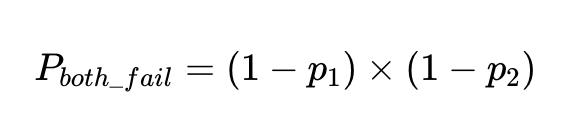
Se abbiamo N esecuzioni con questi client, il numero totale di fallimenti è
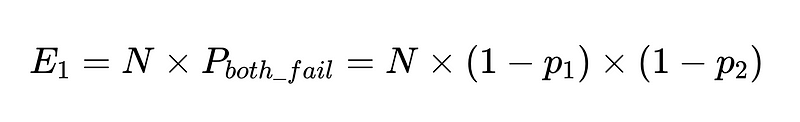
Quindi, per 10,000 esecuzioni tra due lavoratori indipendenti con una precisione del 90%, il numero previsto di errori è 100.
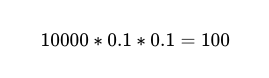
Tuttavia, ancora non lo sappiamo. Quale Di queste 10,000 telefonate, 100 sono veri e propri fallimenti.
Possiamo combinare quattro estensioni di questa idea per fornire una soluzione più solida che fornisca sicurezza in qualsiasi risposta data:
- Classificatore di base (risoluzione semplice sopra)
- Backup (risoluzione semplice sopra)
- Controllore schema (ad esempio risoluzione 0.7)

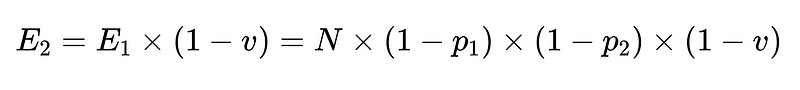
- Infine, un validatore negativo (n = accuratezza 0.6 ad esempio)
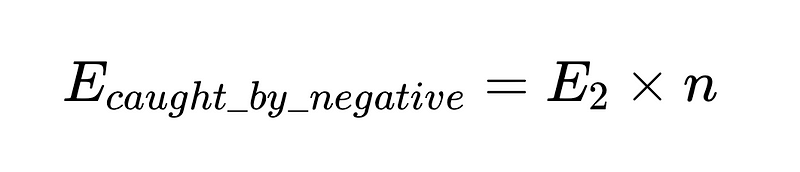
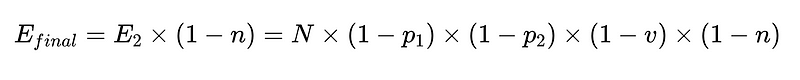
Per metterlo nel codice (Il magazzino completo), possiamo usare Python di base:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESCombinando queste operazioni con la logica, Booleano In parole povere, possiamo ottenere una precisione simile e la stessa affidabilità in ogni risposta:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Logica decisionale: una spiegazione passo passo
Fase 1: quando il sistema di controllo qualità fallisce
if not validation_result:Ciò significa: "Se il nostro esperto di controllo qualità (revisore) rifiuta l'analisi iniziale, non fidatevi". Il sistema tenta quindi di utilizzare al suo posto l'opinione di riserva. Se anche questa verifica non riesce, il caso viene segnalato per la revisione da parte di uno specialista umano. Questa procedura garantisce che non si faccia affidamento su dati inesatti.
In parole povere: "Se qualcosa non va nella nostra prima risposta, proviamo il nostro metodo di riserva. Se il dubbio persiste, chiediamo a un esperto umano di intervenire". In questo modo si garantisce la corretta gestione dei casi complessi.
Fase 2: affrontare le discrepanze
if negative_check == 'no' and primary_result['call_type'] is not None:Questo passaggio verifica un tipo specifico di discrepanza: "Il nostro verificatore negativo indica che non dovrebbe esserci un tipo call, ma il nostro analista fondamentale ha comunque trovato un tipo put".
In questi casi, il sistema si affida all'analista di fallback per raggiungere il pareggio:
- Se l'analista di backup concorda che non esiste alcun tipo di chiamata, la stessa viene inviata all'elemento umano.
- Se l'analista di riserva concorda con l'analista principale, allora la valutazione viene accettata, ma con un livello di sicurezza medio.
- Se l'analista di backup ha un tipo di chiamata diverso ← viene inviato all'elemento umano
È come dire: "Se un esperto dice 'questo non è classificabile' ma un altro dice che lo è, abbiamo bisogno di un giudice decisivo o di un giudice umano". Questo meccanismo è necessario per garantire una classificazione accurata del tipo di chiamata e ridurre i potenziali errori.
Fase 3: Quando gli esperti sono d'accordo
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Quando sia l'analista primario che quello di backup giungono in modo indipendente alla stessa conclusione, il sistema la contrassegna come "alta confidenza": questo è lo scenario migliore. Questa situazione ideale si verifica quando più analisi sono decisamente coerenti.
In parole povere: "Se due esperti diversi, utilizzando metodi diversi in modo indipendente, giungono alla stessa conclusione, possiamo essere abbastanza sicuri che la loro conclusione sia corretta". Ciò rappresenta il consenso degli esperti, il che è un forte indicatore di accuratezza e affidabilità.
Fase 4: Elaborazione predefinita
Se non si verifica nessuna delle condizioni speciali, il sistema utilizza di default il risultato dell'analista primario con un livello di confidenza "medio". Se l'analista principale non è in grado di identificare il tipo di chiamata, segnala il caso affinché venga esaminato da un analista umano specializzato.
L’importanza di questo approccio nella riduzione degli errori
Questa logica contribuisce a costruire un sistema forte:
- Riduzione dei falsi positiviIl sistema garantisce un elevato livello di affidabilità solo quando più metodi concordano, riducendo notevolmente i falsi allarmi.
- Scoprire le contraddizioniQuando parti diverse del sistema presentano divergenze, la fiducia diminuisce o la questione viene inoltrata a revisori umani, garantendo che nessun potenziale problema venga trascurato.
- Escalation intelligenteI revisori umani vedono solo i casi che necessitano realmente della loro competenza, aumentando l'efficienza del processo di revisione e riducendo lo stress delle risorse umane.
- Designazione di trustI risultati includono il livello di confidenza del sistema, consentendo ai processi successivi di trattare in modo diverso i risultati con confidenza elevata rispetto a quelli con confidenza media, il che è fondamentale per prendere decisioni informate.
Questo approccio è simile al modo in cui l'elettronica utilizza circuiti ridondanti e meccanismi di voto per impedire che errori causino guasti al sistema. Nei sistemi di intelligenza artificiale, questo tipo di logica di integrazione ponderata può ridurre significativamente i tassi di errore, utilizzando al contempo i revisori umani in modo efficiente solo laddove aggiungono il massimo valore. In questo modo si garantisce l'ottimizzazione delle risorse e la riduzione simultanea degli errori, ottenendo un sistema più affidabile e preciso.
Esempio
Nel 2015, il Dipartimento idrico della città di Filadelfia ha pubblicato Statistiche sulle chiamate dei clienti per categoria. Comprendere le chiamate dei clienti è un processo molto comune che gli agenti devono affrontare. Invece di far ascoltare ogni telefonata del cliente a un essere umano, un agente può ascoltare la chiamata molto più rapidamente, estrarre informazioni e categorizzare la chiamata per ulteriori analisi dei dati. Per la gestione delle risorse idriche questo è importante perché prima vengono identificati i problemi critici, prima potranno essere risolti.
Possiamo creare un'esperienza. Ho utilizzato un modello linguistico di grandi dimensioni (LLM) per generare trascrizioni false delle telefonate in questione chiedendo: "Data la seguente classe, genera una versione breve di quella telefonata: Ecco alcuni di questi esempi con il file completo disponibile. qui:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Ora, possiamo impostare l'esperimento con una valutazione più tradizionale utilizzando un modello linguistico di grandi dimensioni come giudice (Implementazione completa qui):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typePassando solo il testo a un modello linguistico di grandi dimensioni (LLM), possiamo isolare la vera conoscenza della classe dalla classe estratta che viene restituita e confrontarla.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultL'esecuzione di questa operazione sull'intero set di dati sintetici utilizzando Claude 3.7 Sonnet (il modello più recente, al momento in cui scrivo) garantisce prestazioni molto elevate, con il 91% delle chiamate classificate accuratamente:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Se si trattasse di chiamate reali e non avessimo alcuna conoscenza pregressa della categoria, dovremmo comunque esaminare tutte le 100 telefonate per trovare le 9 chiamate classificate erroneamente.
Applicando il nostro potente circuito decisionale sopra, otteniamo risultati di accuratezza simili insieme a fiducia In quelle risposte. In questo caso, la precisione complessiva è dell'87%, ma nelle nostre risposte ad alta confidenza la precisione è del 92.5%.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Abbiamo bisogno del 100% di precisione nelle nostre risposte ad alta affidabilità, quindi c'è ancora del lavoro da fare. Ciò che questo approccio ci consente di fare è approfondire Motivo Imprecisione delle risposte con elevato grado di affidabilità. In questo caso, affermazioni deboli e semplici capacità di verifica non riescono a cogliere tutti i problemi, causando errori di classificazione. Queste capacità possono essere migliorate in modo iterativo per raggiungere una precisione del 100% nelle risposte ad alta confidenza.
Miglioramenti al sistema di filtraggio per aumentare l'affidabilità dei risultati.
Il sistema attuale classifica le risposte come "ad alta confidenza" quando gli analisti primari e di riserva concordano. Per ottenere una maggiore accuratezza, dobbiamo essere più selettivi su ciò che è considerato "elevata confidenza".
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Aggiungendo ulteriori criteri di qualificazione otterremo meno risultati “ad alta confidenza”, ma saranno più accurati. Questo miglioramento del sistema di filtraggio mira a ridurre gli errori e ad aumentare l'affidabilità dei dati classificati come di alta qualità.
Tecniche di verifica aggiuntive: miglioramento dell'accuratezza dell'analisi
Ecco alcune altre idee per migliorare il processo di convalida e analisi dei dati:
Analizzatore terziarioAggiungere un terzo metodo di analisi indipendente. Questo metodo funge da ulteriore livello di verifica, confrontando i risultati di due diversi metodi analitici con il risultato di un terzo metodo, per garantire una maggiore accuratezza e ridurre la possibilità di errori.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Corrispondenza di modelli storici:Confronta i risultati con quelli storicamente corretti (si pensi alla ricerca vettoriale). Questa tecnica utilizza come riferimento dati storici affidabili e confronta i risultati attuali con essi per individuare eventuali deviazioni o incongruenze. Può essere considerata una sorta di “memoria” analitica, che aiuta a rilevare anomalie o situazioni inaspettate.
if similarity_to_known_correct_cases(primary_result) > 0.95:Test avversarialiApplicare piccole variazioni agli input e verificare se la classificazione rimane stabile. Questo metodo mira a testare la robustezza e l'inalterabilità di un sistema di classificazione esponendolo a piccole modifiche nei dati. Se il sistema è molto sensibile a questi cambiamenti, ciò potrebbe indicare potenziali debolezze o distorsioni.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Formula generale per gli interventi umani in un sistema di estrazione LLM
La derivazione completa è disponibile qui..
- N = Numero totale di esecuzioni (10,000 nel nostro esempio)
- p_1 = accuratezza del parser di base (0.8 nel nostro esempio)
- p_2 = accuratezza del parser di fallback (0.8 nel nostro esempio)
- v = efficacia del validatore dello schema (0.7 nel nostro esempio)
- n = efficacia del verificatore negativo (0.6 nel nostro esempio)
- H = numero di interventi umani richiesti
- E_final = errori finali non rilevati
- m = numero di revisori indipendenti
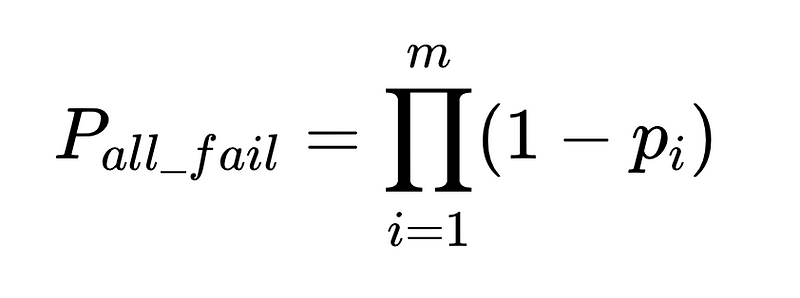
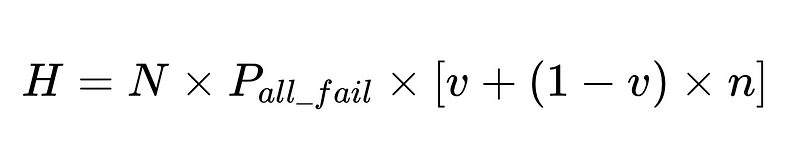
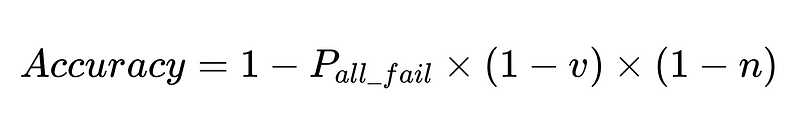
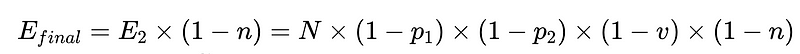
Progettazione ottimale del sistema
L'equazione rivela informazioni chiave sull'accuratezza di un sistema di elaborazione del linguaggio naturale (NLP):
- L'aggiunta di parser riduce i costi generali ma migliora la precisione complessiva.
- La precisione del sistema è limitata da:
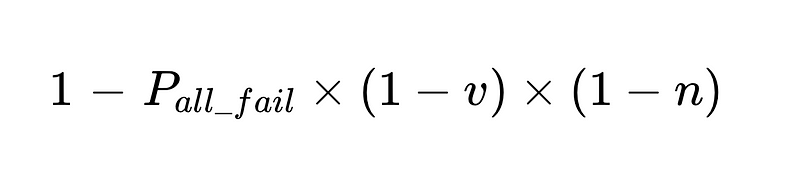
- Gli interventi umani sono proporzionali Direttamente Con un totale di N esecuzioni.
Per esempio:
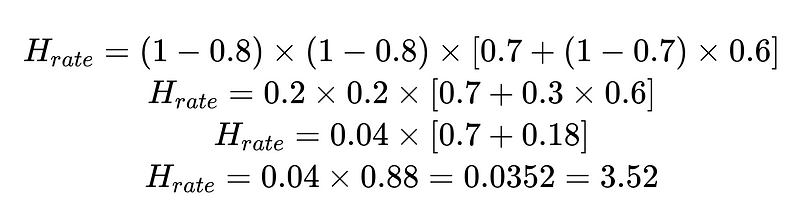
Possiamo utilizzare il tasso di intervento umano calcolato (H_rate) per monitorare l'efficacia della nostra soluzione in tempo reale. Se il tasso di intervento umano inizia a salire oltre il 3.5%, sappiamo che il sistema sta fallendo. Se il tasso di intervento umano diminuisce costantemente fino a raggiungere valori inferiori al 3.5%, sappiamo che le nostre ottimizzazioni funzionano come previsto.
funzione di costo
Possiamo anche creare una funzione di costo che ci aiuti a migliorare il nostro sistema. La funzione di costo è un potente strumento analitico per valutare la performance finanziaria di un sistema e identificare potenziali aree di miglioramento.
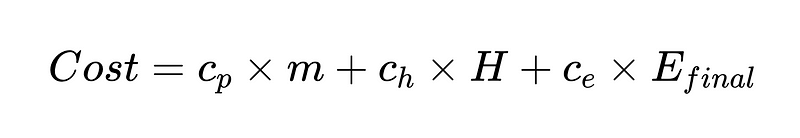
Dove:
- c_p = costo di esecuzione per parser ($ 0.10 nel nostro esempio)
- m = numero di volte in cui viene eseguito il parser (nel nostro esempio 2 * N)
- H = Numero di casi che richiedono l'intervento umano (352 nel nostro esempio)
- c_h = costo di un intervento umano (ad esempio 200 $: 4 ore a 50 $/ora)
- c_e = costo di un errore non rilevato (ad esempio, $ 1000)
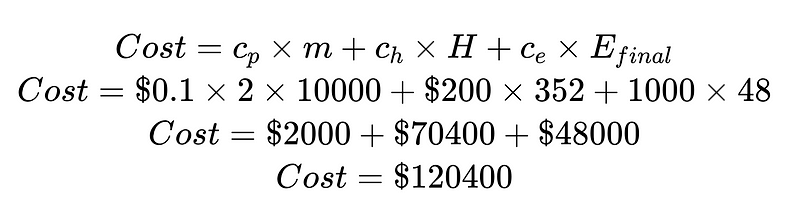
Dividendo il costo per il costo dell'intervento umano e il costo degli errori non rilevati, possiamo migliorare il sistema nel suo complesso. In questo esempio, se il costo dell'intervento umano (70,400 $) è indesiderabile e costoso, possiamo concentrarci sull'aumento dei risultati ad alta confidenza. Se il costo degli errori non rilevati (48,000 $) è indesiderabile e costoso, possiamo introdurre gli analizzatori di sintassi Plus per ridurre il tasso di errori non rilevati.
Naturalmente, le funzioni di costo sono molto utili per esplorare come migliorare le situazioni che descrivono.
Dallo scenario sopra, per ridurre il numero di errori non rilevati, E_final, del 50%, dove
- p1 e p2 = 0.8,
- v = 0.7 e
- n = 0.6
Abbiamo tre opzioni:
- Aggiungere un nuovo parser grammaticale con una precisione del 50% e includerlo come parser secondario. Si noti che questo comporta un compromesso: il costo di esecuzione dei parser grammaticali Plus aumenta insieme al costo dell'intervento umano.
- Migliorare i parser grammaticali esistenti del 10% ciascuno. Ciò potrebbe essere possibile o meno a causa della difficoltà del compito svolto da questi analizzatori sintattici.
- Migliorare il processo di revisione del 15%. Anche in questo caso, i costi aumentano a causa dell'intervento umano.
Il futuro della fiducia nell'intelligenza artificiale: costruire la fiducia attraverso la precisione estrema
Man mano che i sistemi di intelligenza artificiale saranno sempre più integrati in aspetti vitali del business e della società, la ricerca della massima accuratezza diventerà sempre più imperativa, soprattutto nelle applicazioni critiche. Adottando questi approcci al processo decisionale dell'intelligenza artificiale ispirati ai circuiti, possiamo creare sistemi che non solo sono scalabili in modo efficiente, ma guadagnano anche la profonda fiducia che deriva solo da prestazioni costanti e affidabili. Il futuro non risiede in modelli individuali più potenti, ma in sistemi attentamente progettati che combinano molteplici prospettive con la supervisione umana strategica.
Proprio come l'elettronica digitale si è evoluta da componenti inaffidabili fino a creare computer a cui affidare i nostri dati più importanti, anche i sistemi di intelligenza artificiale stanno affrontando un percorso simile. I framework descritti in questo articolo rappresentano i progetti di quella che alla fine diventerà l'architettura standard per l'intelligenza artificiale di importanza critica: sistemi che non solo promettono affidabilità, ma la garantiscono matematicamente. La questione non è più se saremo in grado di costruire sistemi di intelligenza artificiale con una precisione quasi perfetta, ma quanto velocemente potremo implementare questi principi nelle nostre applicazioni più importanti.
I commenti sono chiusi.