

Meta insegna ai modelli di intelligenza artificiale l'arte di distinguere tra comandi importanti e altri.
Modelli di ragionamento come OpenAI o1 e DeepSeek-R1 hanno il problema di pensare troppo. Se le poni una domanda semplice come "Quanto fa 1+1?", ci penserà per qualche secondo prima di rispondere.

Idealmente, i modelli di intelligenza artificiale, come gli esseri umani, dovrebbero essere in grado di stabilire quando fornire una risposta diretta e quando dedicare tempo e risorse aggiuntive per riflettere prima di rispondere. E lo fa nuova tecnologia Presentato dai ricercatori in Meta IA وUniversità dell'Illinois a Chicago Addestrando i modelli ad allocare budget di inferenza in base alla difficoltà della query. Ciò si traduce in risposte più rapide, costi inferiori e una migliore allocazione delle risorse informatiche.
ragionamento costoso
I modelli linguistici di grandi dimensioni (LLM) possono migliorare le loro prestazioni nei compiti di ragionamento quando producono catene di pensiero più lunghe, spesso note come "catene di pensiero" (CoT). Il successo della tecnica della catena di idee ha portato a tutta una serie di tecniche di ridimensionamento temporale dell'inferenza che costringono il modello a "pensare" più a fondo al problema, a generare e rivedere più risposte e a scegliere quella migliore.
Il voto a maggioranza (MV) è uno dei metodi principali utilizzati nei modelli di ragionamento, in cui vengono generate più risposte e viene scelta la risposta più frequentemente richiesta. Il problema di questo approccio è che il modello adotta un comportamento uniforme, trattando ogni input come un difficile problema di ragionamento e consumando risorse inutili per generare più risposte.
Ragionamento intelligente
Il nuovo documento di ricerca propone una serie di tecniche di addestramento che rendono i modelli di ragionamento più efficienti nella risposta. Il primo passaggio è il "voto sequenziale" (SV), in cui il modello interrompe il processo di ragionamento una volta che una determinata risposta è apparsa un certo numero di volte. Ad esempio, al modulo viene chiesto di generare un massimo di otto risposte e di scegliere la risposta che appare almeno tre volte. Se al modello viene fornita la semplice query di cui sopra, è probabile che le prime tre risposte siano simili, il che porta a un arresto anticipato, con conseguente risparmio di tempo e risorse di calcolo.
I loro esperimenti dimostrano che SV supera MV classico nei problemi di matematica competitiva quando genera lo stesso numero di risposte. Tuttavia, SV richiede istruzioni aggiuntive e generazione di codice, rendendolo alla pari con MV in termini di rapporto codice-precisione.
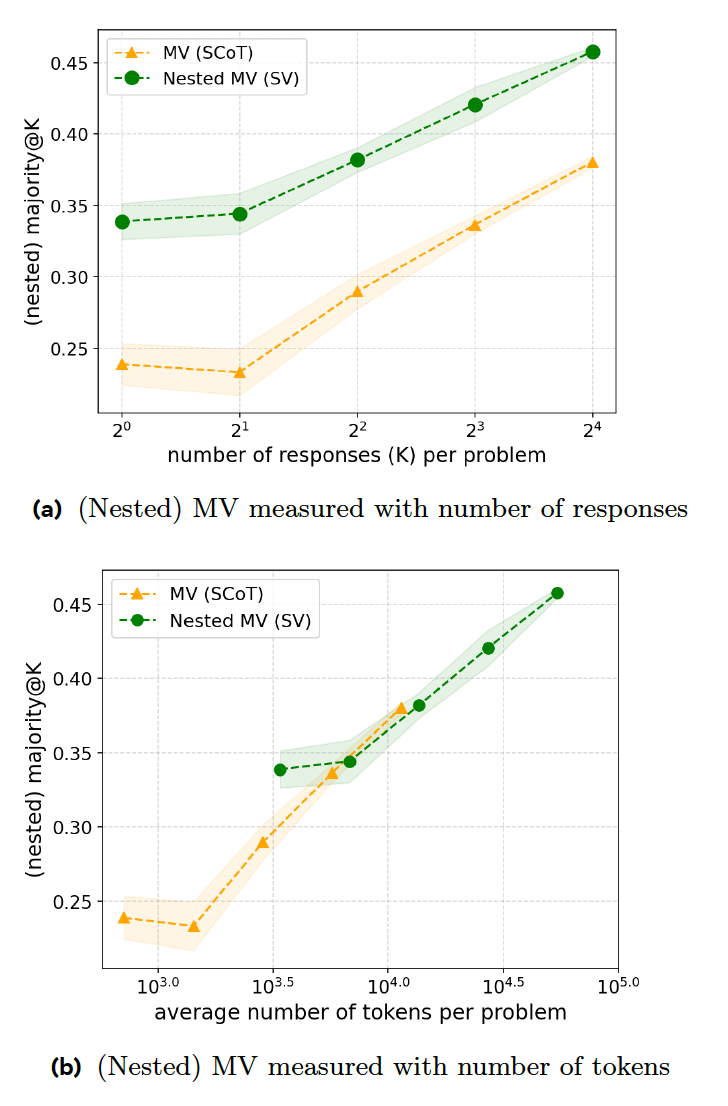
La seconda tecnica, Adaptive Sequential Voting (ASV), migliora l'SV richiedendo al modello di esaminare il problema e di generare più risposte solo quando il problema è difficile. Per problemi semplici (ad esempio un'affermazione 1+1), il modello genera semplicemente un'unica risposta senza passare attraverso il processo di votazione. Ciò rende il modello più efficiente nella gestione sia di problemi semplici che complessi.
Insegnamento rafforzativo
Sebbene entrambe le tecniche SV e ASV migliorino l'efficienza del modello, richiedono una grande quantità di dati etichettati manualmente. Per attenuare questo problema, i ricercatori propongono l'”ottimizzazione delle politiche con vincoli di budget inferenziale” (IBPO), un algoritmo di apprendimento per rinforzo che insegna al modello a regolare la lunghezza dei percorsi di ragionamento in base alla difficoltà della query.
L'IBPO è progettato per consentire ai modelli linguistici di grandi dimensioni (LLM) di migliorare le proprie risposte restando entro i limiti del budget di inferenza. L'algoritmo di apprendimento per rinforzo consente al modello di superare i guadagni ottenuti tramite l'addestramento su dati etichettati manualmente, generando continuamente traiettorie ASV, valutando le risposte e selezionando i risultati che forniscono la risposta corretta e il budget di inferenza ottimale.
I loro esperimenti dimostrano che l'IBPO migliora il fronte di Pareto, il che significa che, per un budget di inferenza fisso, un modello addestrato sull'IBPO supera altre linee di base.
Questi risultati giungono in concomitanza con gli avvertimenti dei ricercatori secondo cui gli attuali modelli di intelligenza artificiale sono in difficoltà. Mentre le aziende faticano a reperire dati di formazione di alta qualità ed esplorare modi alternativi per migliorare i propri modelli.
Una soluzione promettente è l'apprendimento per rinforzo, in cui al modello viene assegnato un obiettivo e gli viene permesso di trovare le proprie soluzioni, in contrapposizione alla messa a punto supervisionata (SFT), in cui il modello viene addestrato su esempi etichettati manualmente.
Sorprendentemente, il modello trova spesso soluzioni a cui gli esseri umani non avevano pensato. Questa è una formula che sembra aver funzionato con DeepSeek-R1, che ha sfidato il predominio dei laboratori di intelligenza artificiale americani.
I ricercatori osservano che "i metodi basati su prompt e SFT faticano a raggiungere l'ottimizzazione e l'efficienza assolute, avvalorando l'ipotesi che SFT da solo non consenta capacità di autocorrezione. Questa osservazione è supportata anche da studi concomitanti, che suggeriscono che questo comportamento di autocorrezione emerge spontaneamente durante l'apprendimento della realtà virtuale (RL) anziché essere generato manualmente da prompt o SFT".
I commenti sono chiusi.