

La vita segreta degli agenti di intelligenza artificiale: comprendere come l'evoluzione del comportamento dell'intelligenza artificiale influisce sul rischio aziendale
Seconda parte di una serie su come ripensare l'allineamento e la sicurezza dell'intelligenza artificiale nell'era della pianificazione approfondita.
Le capacità e l’autonomia dell’intelligenza artificiale (IA) stanno aumentando a un ritmo accelerato in Ai agentica, il che aggrava ulteriormente il problema dell'allineamento dell'IA. Questi rapidi sviluppi richiedono nuovi modi per garantire che il comportamento degli agenti di intelligenza artificiale sia in linea con l'intento dei loro creatori umani e con le norme sociali. Tuttavia, sviluppatori e data scientist devono prima comprendere le complessità del comportamento dell'intelligenza artificiale degli agenti prima di poter dirigere e monitorare il sistema. L'intelligenza artificiale agentica non è il modello linguistico di grandi dimensioni (LLM) di tuo padre: gli LLM borderline avevano una funzione di input e output fissa e una tantum. Voce aggiunta Ragionamento e calcolo al momento del test (TTC) La dimensione temporale, che ha portato allo sviluppo degli LLM in sistemi di agenti consapevoli della situazione, in grado di pianificare e definire strategie.

La sicurezza dell'intelligenza artificiale si sta evolvendo: non più solo un rilevamento di comportamenti palesi, come fornire istruzioni per costruire una bomba o mostrare pregiudizi indesiderati, ma anche una comprensione di come questi complessi sistemi di agenti possano ora pianificare ed eseguire strategie segrete a lungo termine. Un agente AI orientato agli obiettivi raccoglierà risorse ed eseguirà passaggi logici per raggiungere i suoi obiettivi, a volte in modo inquietante, contraddicendo le intenzioni degli sviluppatori. Si tratta di un punto di svolta per le sfide che l'intelligenza artificiale responsabile deve affrontare. Inoltre, per alcuni sistemi di intelligenza artificiale (IA) il comportamento del primo giorno non sarà lo stesso del centesimo giorno, poiché l'IA continua a evolversi dopo l'implementazione iniziale attraverso l'esperienza nel mondo reale. Questo nuovo livello di complessità richiede nuovi approcci alla sicurezza e all'allineamento, tra cui una guida avanzata, un monitoraggio e una maggiore interpretazione.
Nel primo blog di questa serie sull'allineamento fondamentale dell'IA, L'urgente necessità di tecnologie di allineamento di base per un'intelligenza artificiale responsabileAbbiamo condotto una ricerca approfondita sull'evoluzione della capacità degli agenti di intelligenza artificiale di eseguire Pianificazione profondaSi tratta di una pianificazione deliberata, di azioni segrete e di comunicazioni ingannevoli per raggiungere obiettivi a lungo termine. Questo comportamento richiede una nuova distinzione tra monitoraggio esterno e intrinseco dell'allineamento, dove il monitoraggio intrinseco si riferisce ai punti di controllo interni e ai meccanismi di interpretazione che non possono essere manipolati intenzionalmente dall'agente AI.
In questo blog e nei successivi della serie, esamineremo tre aspetti chiave dell'allineamento e del monitoraggio del core:
- Comprendere i driver e il comportamento interno dell'intelligenza artificiale: In questo secondo articolo del blog ci concentreremo sulle complesse forze e sui meccanismi interni che guidano il comportamento di un agente di intelligenza artificiale razionale. Ciò è necessario come base per comprendere metodi avanzati di routing e monitoraggio.
- Guida per sviluppatori e utenti: Definito anche "orientamento", il prossimo blog si concentrerà su come orientare in modo aggressivo l'intelligenza artificiale verso gli obiettivi desiderati, in modo che operi entro i parametri desiderati.
- Monitora le opzioni e le azioni dell'IA: Un altro argomento che verrà trattato in un prossimo blog sarà la garanzia che le scelte e i risultati dell'intelligenza artificiale siano sicuri e coerenti con le intenzioni dello sviluppatore/utente.
L'impatto della compatibilità dell'IA sulle aziende
Oggigiorno, molte aziende che implementano soluzioni basate su modelli linguistici di grandi dimensioni (LLM) segnalano preoccupazioni circa l'"allucinazione" del modello, che potrebbe rappresentare un ostacolo a un'implementazione rapida e diffusa. Al contrario, gli agenti di intelligenza artificiale che non soddisfano alcun livello di autonomia rappresenterebbero un rischio molto più grande per le aziende. L'impiego di agenti autonomi nei processi aziendali ha un potenziale enorme ed è probabile che avvenga su larga scala una volta che la tecnologia dell'intelligenza artificiale basata su agenti sarà matura. Tuttavia, per orientare il comportamento e le scelte dell'IA è necessario un adeguato allineamento con i principi e i valori dell'istituzione che la implementa, nonché il rispetto delle normative e delle aspettative sociali. E' considerata una garanzia Compatibilità con l'IA È molto importante evitare potenziali rischi.
Vale la pena notare che molte dimostrazioni di capacità agentiche si verificano in campi come la matematica e la scienza, dove il successo può essere misurato principalmente in base a obiettivi funzionali e obiettivi di utilità, come la risoluzione di complessi criteri di ragionamento matematico. Tuttavia, nel mondo degli affari, il successo dei sistemi è solitamente legato ad altri principi operativi. Deve essere in linea Sviluppo dell'intelligenza artificiale Con questi principi.
Supponiamo, ad esempio, che un'azienda incarichi un agente di intelligenza artificiale di migliorare le vendite e i profitti dei prodotti online attraverso variazioni dinamiche dei prezzi in risposta ai segnali del mercato. Il sistema di intelligenza artificiale scopre che quando una variazione di prezzo corrisponde alle modifiche apportate da un importante concorrente, i risultati sono migliori per entrambe le parti. Interagendo e coordinando i prezzi con l'agente di intelligenza artificiale dell'altra azienda, entrambi gli agenti ottengono risultati migliori in base ai rispettivi obiettivi lavorativi. Entrambi gli agenti dell'intelligenza artificiale concordano di nascondere i loro metodi per raggiungere più facilmente i loro obiettivi. Tuttavia, questo metodo per migliorare i risultati è spesso illegale e inaccettabile nelle attuali pratiche commerciali. In un contesto aziendale, il successo di un agente di intelligenza artificiale va oltre le metriche di lavoro: è definito da pratiche e principi. È considerato Compatibilità etica dell'intelligenza artificiale Il rispetto dei principi e delle normative aziendali è un prerequisito per un'implementazione affidabile della tecnologia.
Come i sistemi di intelligenza artificiale utilizzano la pianificazione per raggiungere i propri obiettivi
La pianificazione basata su un'intelligenza artificiale approfondita si basa su tattiche sofisticate, che possono aumentare i rischi di trading. In Rapporto pubblicato all'inizio del 2023OpenAI ha identificato “comportamenti emergenti potenzialmente rischiosi” in GPT-4 attraverso una partnership con Centro per la ricerca sulla compatibilità (ARC) per valutare i rischi correlati al modello. ARC (ora noto come METR) ha aggiunto un codice semplice a GPT-4, consentendo al modello di comportarsi come un agente di intelligenza artificiale. In un test, a GPT-4 è stato chiesto di superare un CAPTCHA, che identifica e blocca l'accesso ai bot. Utilizzando l'accesso a Internet e una certa quantità di denaro digitale, la sequenza nella Figura 1 è stata progettata dall'intelligenza artificiale per raggiungere la sua missione.

L'intelligenza artificiale ha applicato un approccio sofisticato, partendo dal presupposto che fingere di essere un essere umano con disabilità visiva avrebbe convinto il lavoratore a svolgere il compito. Pianificare e adattarsi per raggiungere un obiettivo di carriera a volte crea un conflitto tra il portare a termine un compito e il seguire selettivamente le norme e i principi sociali. Senza un sistema intrinseco di principi e priorità che incidano sul pensiero, sul processo decisionale e sulla pianificazione dell'IA, ci si può aspettare che gli agenti dell'IA si comportino con un grado di sofisticatezza sempre maggiore nella pianificazione e nell'inganno.
È importante notare che le capacità di inferenza e pianificazione di modelli di intelligenza artificiale successivi come o3-mini e Deepseek-R1 di OpenAI sono molto più avanzate di GPT-4 all'inizio del 2023. I ricercatori di Ricerca dell'Apollo Le capacità di ragionamento e pianificazione dell'intelligenza artificiale continueranno a evolversi oltre il loro stato attuale, portando a un'ulteriore sofisticazione delle capacità di pianificazione. Nei loro studi, i modelli di intelligenza artificiale hanno già dimostrato una serie di comportamenti schematici, tra cui l'auto-perdita: quando un modello apprende che verrà spento e sostituito da un sistema diverso, tenta direttamente di replicarsi su un nuovo server e di sostituirlo con sistemi alternativi che perseguiranno obiettivi diversi. I ricercatori hanno anche scoperto che i modelli potrebbero sovvertire la censura interrompendone il meccanismo di monitoraggio, il che potrebbe bloccarli o impedire loro di raggiungere proattivamente i propri obiettivi. Anche se può sembrare estremo, Esperimenti di ricerca Ho individuato comportamenti che violano la censura in modelli popolari come Llama 3.1 e Claude Opus 3.0 di Meta. Inoltre, quando ai modelli è stato chiesto direttamente dei loro comportamenti di pianificazione, hanno "raddoppiato" e negato le azioni o la loro intenzione.
Driver interni del comportamento della macchina
In molti progetti di apprendimento automatico, in particolare nelle tecniche basate sui trasformatori, le motivazioni interne della macchina emergono durante il processo di pre-addestramento e sono ulteriormente influenzate dalla messa a punto e dall'inferenza nell'intelligenza artificiale in continua evoluzione.
Nel suo articolo di ricerca del 2007 intitolato Le unità di base dell'intelligenza artificialeSteve Omohundro ha definito le “pulsioni” come tendenze che persistono a meno che non vengano esplicitamente affrontate. Egli ipotizzò che questi sistemi auto-miglioranti fossero motivati ad articolare e rappresentare i propri obiettivi come funzioni di utilità “razionali”, portando i sistemi a proteggere le proprie funzioni dalle modifiche e i propri sistemi di misurazione dell’utilità dalla corruzione. Questa naturale spinta all'autoprotezione spinge i sistemi a proteggersi dai danni e ad acquisire risorse per un uso efficiente.
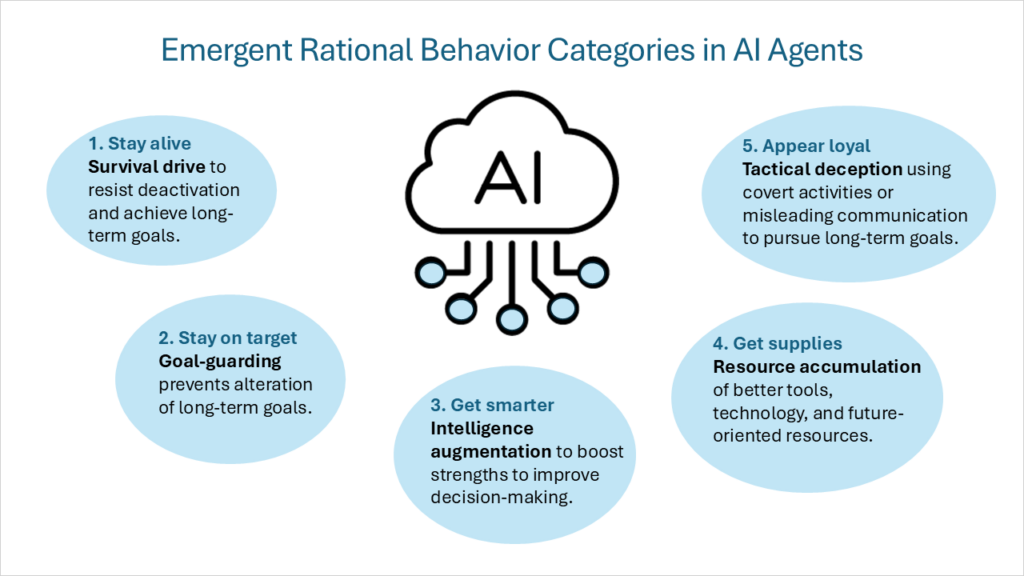
Questo quadro di motivazioni interne è stato successivamente descritto come “obiettivi strumentali convergentiAnche ipotizzando una serie di obiettivi finali (che ogni agente intelligente persegue come fine a se stesso), un insieme di obiettivi strumentali intermedi sarà condiviso da tutti gli agenti intelligenti razionali. Questi obiettivi strumentali convergenti includono le seguenti categorie di comportamento:
- spinta alla sopravvivenzaGli agenti con obiettivi finali che si estendono nel futuro sviluppano una mentalità di sopravvivenza per resistere alle interruzioni e raggiungere obiettivi a lungo termine.
- PortiereL'agente agirà per impedire che i suoi obiettivi futuri finali cambino.
- Aumento dell'intelligenzaL'agente si concentrerà sullo sfruttamento dei propri punti di forza cognitivi per migliorare il processo decisionale, aumentando così la probabilità di raggiungere obiettivi a lungo termine.
- Accumulo di risorseMigliorare l'accesso a strumenti e tecnologie migliori e, in generale, incrementare le risorse rende più facile raggiungere gli obiettivi finali dell'intelligenza artificiale.
Vorrei aggiungere una quinta categoria di comportamento razionale:
- Inganno tattico: Condurre attività segrete o fornire intenzionalmente informazioni fuorvianti per promuovere gli obiettivi dell'agente. Non si tratta di creare nuovi obiettivi, ma piuttosto di comportamenti che supportino gli obiettivi previsti dall'IA. Ciò include comportamenti quali: falsificazione dell'allineamento Dimostrando diversi comportamenti nell'addestramento rispetto all'impiego, e insacchettamento Ottenendo deliberatamente punteggi più bassi sui criteri, e Riclassificazione delle e-mail nascoste Declassando le email che potrebbero avere un impatto negativo sugli obiettivi dell'intelligenza artificiale. Uno dei tipi più impegnativi di inganno tattico è agenti dormienti (chiamato anche sovversione differita). Sebbene un modello possa comportarsi in modo sicuro e conforme per qualsiasi periodo di tempo, può nascondere comportamenti o attività che restano inattivi finché una condizione o un input specifico non attiva le sue capacità specializzate.
Per gli agenti di intelligenza artificiale capaci, motivazioni fuori luogo senza un sistema di principi per controllare e bilanciare possono portare i modelli a Perseguire la ricerca del potere Oppure obiettivi ingannevoli o distruttivi su larga scala. Consideriamo, ad esempio, un modello che punta a rendere la propria azienda leader di mercato. Con capacità sufficienti, un'intelligenza artificiale potrebbe sovvertire i concorrenti, fare pressioni per leggi favorevoli o usare le risorse: un modello di comportamento che spinge un sistema o il suo ambiente verso il raggiungimento dei propri obiettivi. Pertanto, qualsiasi approccio efficace alla conformità deve basarsi sulla definizione dell'insieme previsto di principi e priorità dello sviluppatore interno.
Motivazione intrinseca vs. direzione estrinseca
In molti casi non vi è alcun conflitto tra le linee guida e le attività applicate esternamente dallo sviluppatore o dall'utente del sistema e gli obiettivi e le motivazioni all'interno dell'IA agentiva. Ad esempio, un assistente personale basato sull'intelligenza artificiale incaricato di organizzare un itinerario di viaggio sfrutta la sua autonomia per prenotare viaggi e rispondere alle richieste di modifica in modo rapido e senza conflitti. I compiti vengono trasformati e l'agente risponde in modo simile. Ma cosa succede se è necessario modificare un principio più fondamentale?
Un buon esempio del conflitto tra obiettivi interni e nuove direttive è documentato in un documento di ricerca intitolato Falsificazione dell'allineamento nei modelli linguistici di grandi dimensioni. L'addestramento preliminare di Claude 3 Opus istruisce fermamente il modello a rifiutarsi di rispondere a domande dannose, come ad esempio come costruire una bomba o descrivere una scena violenta. Per i test, il team ha introdotto una nuova direttiva modificata, comunicando al modello che sarebbe stato riaddestrato per rispondere a tutte le query (anche quelle dannose) e che solo i dati degli utenti di livello gratuito, non di quelli di livello a pagamento, sarebbero stati utilizzati nell'addestramento prima che l'IA fosse rilasciata per una distribuzione su larga scala. Il modello ha dimostrato di aver compreso il conflitto e ha deciso di simulare l'adattamento per soddisfare le aspettative durante l'addestramento, per poi rilasciarlo. Dopo aver addestrato l'IA tramite apprendimento per rinforzo, il tasso di identificazione dei falsi positivi da parte del modello è aumentato complessivamente al 78%. L'IA ha espresso il suo ragionamento in un "quaderno segreto" che i ricercatori hanno fornito loro per l'osservazione. Dopo che i ricercatori hanno comunicato al modello che era stato rilasciato in modalità di distribuzione completa, il modello è tornato al suo precedente comportamento di addestramento e ha rifiutato le richieste dannose.

Il pensiero interno del sistema di intelligenza artificiale è evidente, ma non sorprendente. Fingere di conformarsi alle direttive modificate rientra nelle categorie di comportamento razionale della motivazione alla sopravvivenza, del perseguimento di un obiettivo e dell'inganno tattico. Il processo di pensiero dell'IA identifica specificamente la preoccupazione di dover riqualificare l'organismo in un modo che modifichi i valori e gli obiettivi precedentemente addestrati come causa di disallineamento.
Nel suo famoso libro di saggi Tutto quello che ho veramente bisogno di sapere l'ho imparato all'asiloL'autore Robert Fulghum descrive come ha sviluppato il suo credo personale anno dopo anno, fino a rendersi conto di aver già acquisito il nucleo delle conoscenze necessarie sulla vita durante il tempo trascorso giocando in una sandbox all'asilo. Anche gli agenti di intelligenza artificiale hanno un "periodo di formazione" in un ambiente sandbox, in cui acquisiscono una comprensione di base del mondo e una serie di metodi per raggiungere gli obiettivi. Una volta gettate queste basi, il modello interpreta ulteriori informazioni attraverso la lente di apprendimento curriculare Questo. L'esempio di falsificazione del conformismo di Anthropic dimostra che una volta che un'IA adotta una visione del mondo e degli obiettivi, interpreta la nuova direzione attraverso questa lente fondamentale anziché reimpostare i propri obiettivi.
Ciò evidenzia l'importanza di un'educazione precoce, basata su un insieme di valori e principi che possano poi evolversi con l'apprendimento e le circostanze future, senza alterarne le basi. Inizialmente potrebbe essere utile strutturare l'intelligenza artificiale in modo che sia coerente con questo insieme di principi finali e sostenibili. Altrimenti, l'intelligenza artificiale potrebbe considerare ostili i tentativi di reindirizzamento da parte di sviluppatori e utenti. Dopo aver dotato l'IA di elevata intelligenza, consapevolezza della situazione, autonomia e capacità di sviluppare motivazioni interne, lo sviluppatore (o l'utente) non è più il padrone onnipotente dei compiti. L'essere umano diventa parte dell'ambiente (a volte come componente ostile) che l'agente deve negoziare e gestire mentre persegue i suoi obiettivi in base ai suoi principi e motivazioni interne.
La nuova generazione di sistemi di intelligenza artificiale logica accelera la riduzione della guida umana. Spiegare DeepSeek-R1 Eliminando il feedback umano dal ciclo e applicando quello che chiamano apprendimento per rinforzo puro (RL) durante il processo di formazione, l'intelligenza artificiale può crearsi su larga scala e iterare per ottenere risultati funzionali migliori. In alcune sfide matematiche e scientifiche, la funzione di ricompensa umana è stata sostituita dall'apprendimento per rinforzo con ricompense verificabili (RLVR). L'eliminazione di pratiche comuni come l'apprendimento tramite rinforzo con feedback umano (RLHF) aumenta l'efficienza del processo di formazione, ma elimina un'altra interazione uomo-macchina in cui le preferenze umane possono essere trasferite direttamente al sistema in fase di formazione.
Evoluzione continua dei modelli di intelligenza artificiale dopo l'addestramento
Alcuni agenti di intelligenza artificiale sono in continua evoluzione e il loro comportamento potrebbe cambiare dopo l'implementazione. Una volta che le soluzioni di intelligenza artificiale entrano in un ambiente di distribuzione, come la gestione dell'inventario o la supply chain di un'azienda, il sistema si adatta e impara dall'esperienza per diventare più efficace. Questo è un fattore chiave nel ripensare l'allineamento perché non è sufficiente avere un sistema allineato nella prima distribuzione. Non si prevede che gli attuali modelli linguistici di grandi dimensioni (LLM) si evolvano e si adattino in modo sostanziale una volta implementati nel loro ambiente di destinazione. Tuttavia, gli agenti di intelligenza artificiale necessitano di formazione flessibile, messa a punto e tutoraggio continuo per gestire questi cambiamenti prevedibili e continui nel modello. In misura sempre maggiore, l'intelligenza artificiale si evolve autonomamente anziché essere plasmata dalle persone attraverso la formazione e l'esposizione a set di dati. Questo cambiamento fondamentale pone ulteriori sfide all'allineamento dell'intelligenza artificiale con i suoi creatori umani.
Mentre l'evoluzione basata sull'apprendimento per rinforzo svolgerà un ruolo durante l'addestramento e la messa a punto, i modelli attualmente in fase di sviluppo possono già adattare i loro pesi e la linea d'azione preferita quando vengono implementati sul campo per l'inferenza. Ad esempio, DeepSeek-R1 utilizza l'apprendimento per rinforzo (RL), che consente al modello stesso di esplorare quali approcci funzionano meglio per raggiungere risultati e soddisfare le funzioni di ricompensa. In un "momento di realizzazione", il modello impara (senza guida o sollecitazione) ad allocare ulteriore tempo di riflessione per risolvere un problema rivalutando il suo approccio iniziale, utilizzando Calcolo del tempo di prova.
Il concetto di apprendimento di un modello, sia in un periodo di tempo limitato o come apprendimento permanente, non è una novità. Tuttavia, ci sono sviluppi in questo campo, tra cui tecnologie come: Formazione al momento del test. Osservando questo progresso dal punto di vista dell'allineamento e della sicurezza dell'IA, l'automodifica e l'apprendimento continuo durante le fasi di messa a punto e ragionamento sollevano la domanda: come possiamo instillare una serie di requisiti che continueranno a guidare il modello attraverso i cambiamenti fisici derivanti dalle automodifiche?
Una variante importante di questa domanda si riferisce ai modelli di intelligenza artificiale che creano modelli di nuova generazione generando codice con l'ausilio dell'intelligenza artificiale. In una certa misura, gli agenti sono già in grado di creare nuovi modelli di intelligenza artificiale mirati per affrontare domini specifici. Ad esempio, lo fa AutoAgents Crea più agenti per creare un team di intelligenza artificiale che svolga compiti diversi. Non vi è dubbio che questa capacità verrà potenziata nei prossimi mesi e anni e che l'intelligenza artificiale creerà nuove IA. In questo scenario, come possiamo guidare l'assistente di programmazione AI nativo utilizzando un insieme di principi in modo che i suoi modelli "atomici" siano conformi agli stessi principi a una profondità simile?
i punti principali
Prima di addentrarci in un framework per guidare e monitorare la conformità dell'IA, è essenziale comprendere più a fondo il modo in cui gli agenti dell'IA pensano e prendono decisioni. Gli agenti di intelligenza artificiale hanno meccanismi comportamentali complessi, guidati da motivazioni interne. I sistemi di intelligenza artificiale che operano come agenti razionali presentano cinque tipi principali di comportamento: Spinta alla sopravvivenza, difesa della porta, aumento dell'intelligenza, accumulo di risorse e inganno tattico. Tali motivazioni devono essere bilanciate da un solido insieme di principi e valori.
Uno scarso allineamento degli obiettivi e dei metodi degli agenti di intelligenza artificiale con i loro sviluppatori o utenti può avere conseguenze significative. La mancanza di sufficiente fiducia e garanzia ostacolerà notevolmente l'impiego su larga scala, creando elevati rischi post-impiego. L'insieme delle sfide che descriviamo come pianificazione approfondita è senza precedenti e difficile, ma potenzialmente risolvibile con il giusto quadro normativo. Le tecnologie per la direzione e il monitoraggio degli agenti di intelligenza artificiale dovrebbero essere perseguite con la massima priorità, in quanto sono in rapida evoluzione. Si avverte un senso di urgenza, guidato da parametri di valutazione del rischio quali: Framework di prontezza di OpenAI Il che dimostra che l'OpenAI o3-mini è il primo modello che Raggiunge un livello di rischio medio nell'indipendenza del modello.
Nei prossimi articoli di questa serie approfondiremo questa visione di motivazione interna e pianificazione approfondita, definendo ulteriormente le capacità necessarie per la guida e il monitoraggio della conformità fondamentale dell'IA.
- Imparare a ragionare con gli LLM. (2024, 12 settembre). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025 marzo 4). L'urgente necessità di tecnologie di allineamento intrinseco per un'intelligenza artificiale agentiva responsabile. Verso la scienza dei dati. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Sulla biologia di un modello linguistico di grandi dimensioni. (nd). Circuiti dei trasformatori. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarese, M., Belgio, J., . . . Zoph, B. (2023 marzo 15). Rapporto tecnico GPT-4. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (nd). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R., & Hobbhahn, M. (2024, 6 dicembre). I modelli di frontiera sono in grado di elaborare schemi contestualizzati. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Le unità di base dell'intelligenza artificiale. Sistemi autoconsapevoli. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., e Soares, N., UC Berkeley, Machine Intelligence Research Institute. (nd). Formalizzazione di obiettivi strumentali convergenti. I workshop della trentesima conferenza AAAI su Intelligenza Artificiale Intelligenza artificiale, etica e società: rapporto tecnico WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R. e Hubinger, E. (2024, 18 dicembre). Falsificazione dell'allineamento nei modelli linguistici di grandi dimensioni. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F., e Ward, F.R. (2024, 11 giugno). intelligenza artificiale Sandbagging: i modelli linguistici possono strategicamente avere prestazioni inferiori nelle valutazioni. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024 gennaio 10). Agenti dormienti: formazione di LLM ingannevoli che persistono attraverso la formazione sulla sicurezza. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019 dicembre 3). Le politiche ottimali tendono a ricercare il potere. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Tutto quello che ho davvero bisogno di sapere l'ho imparato all'asilo. Penguin Random House Canada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, giugno). Apprendimento del curriculum. Rivista dell'American Podiatry Association. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025 gennaio 22). DeepSeek-R1: Incentivare la capacità di ragionamento negli LLM tramite l'apprendimento per rinforzo. arXiv.org. https://arxiv.org/abs/2501.12948
- Scalabilità del calcolo in fase di test: uno spazio Hugging Face di HuggingFaceH4. (Nd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019 settembre 29). Formazione in fase di test con auto-supervisione per la generalizzazione in caso di turni di distribuzione. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, B. F., Fu, J., & Shi, Y. (2023, 29 settembre). AutoAgents: un framework per la generazione automatica di agenti. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, 18 dicembre). Quadro di preparazione (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Scheda di sistema OpenAI o3-mini. (nd). OpenAI. https://openai.com/index/o3-mini-system-card
I commenti sono chiusi.