

Come puoi garantire che le tue soluzioni di intelligenza artificiale funzionino come previsto?
Una breve introduzione alle valutazioni dell'IA
L'intelligenza artificiale generativa (GenAI) si sta evolvendo rapidamente e non si limita più solo a divertenti chatbot o alla generazione di immagini spettacolari. Il 2025 è l'anno in cui l'attenzione sarà rivolta a trasformare l'entusiasmo per l'intelligenza artificiale in valore reale. Le aziende di tutto il mondo sono alla ricerca di modi per integrare e sfruttare GenAI nei loro prodotti e nelle loro attività, per servire meglio gli utenti, migliorare l'efficienza, mantenere la competitività e stimolare la crescita. Grazie alle API e ai modelli pre-addestrati dei principali fornitori, integrare GenAI sembra più facile che mai. Ma ecco il nocciolo della questione: Il fatto che l'integrazione sia semplice non significa che le soluzioni di intelligenza artificiale funzioneranno come previsto una volta implementate.

I modelli predittivi non sono una novità: noi esseri umani prevediamo eventi da anni, iniziando ufficialmente con le statistiche. Tuttavia, GenAI sta rivoluzionando il campo delle previsioni per molteplici ragioni.:
- Non è necessario addestrare un proprio modello o essere uno scienziato dei dati per creare soluzioni di intelligenza artificiale.
- L'intelligenza artificiale è ora facile da usare attraverso le interfacce di chat e da integrare tramite API.
- Scatenando molte cose che prima non era possibile fare o che erano davvero difficili da fare.
Tutte queste cose rendono GenAI è molto entusiasmante, ma anche rischioso.. A differenza dei software tradizionali, o persino del classico apprendimento automatico, GenAI offre un nuovo livello di imprevedibilità. Non stai implementando una logica deterministica, stai utilizzando un modello addestrato su enormi quantità di dati, sperando che risponda come necessario. Quindi, come facciamo a sapere se un sistema di intelligenza artificiale sta facendo ciò che intendiamo? Come facciamo a sapere se è pronto per essere utilizzato? La risposta è la valutazione, un concetto che esploreremo in questo post:
- Perché i sistemi Genai non possono essere testati allo stesso modo del software tradizionale o persino del classico apprendimento automatico (ML)
- Perché le valutazioni sono essenziali per comprendere la qualità del tuo sistema di intelligenza artificiale e non facoltative (a meno che non ti piacciano le sorprese)
- Diversi tipi di valutazione e tecniche per applicarle nella pratica
Che tu sia un product manager, un ingegnere o chiunque lavori o sia interessato all'intelligenza artificiale, spero che questo post ti aiuti a capire come pensare in modo critico alla qualità dei sistemi di intelligenza artificiale (e perché le valutazioni sono essenziali per raggiungere tale qualità!).
L'intelligenza artificiale generativa non può essere testata come i software tradizionali, né come l'apprendimento automatico classico.
Nello sviluppo software tradizionaleI sistemi seguono una logica deterministica: Se accade X, allora accadrà Y. - Sempre. A meno che non si verifichi un problema con la tua piattaforma o non si introduca un bug nel tuo codice... ecco perché aggiungiamo test, monitoraggio e avvisi. I test unitari vengono utilizzati per convalidare piccoli blocchi di codice, i test di integrazione per garantire che i componenti funzionino bene insieme e il monitoraggio per rilevare eventuali problemi in produzione. Il test tradizionale del software è come controllare il funzionamento di una calcolatrice. Inserisci 2 + 2 e ti aspetti 4. Chiaro e inevitabile, vero o falso.
Tuttavia, l'apprendimento automatico e l'intelligenza artificiale introducono indeterminismo e probabilità. Invece di specificare esplicitamente il comportamento attraverso regole, addestriamo i modelli ad apprendere schemi dai dati. Nell'intelligenza artificiale, se si verifica X, l'output non è più una Y codificata in modo rigido, ma una previsione con un certo grado di probabilità, basata su ciò che il modello ha appreso durante l'addestramento.. Questo può essere molto potente, ma introduce anche incertezza: input identici possono avere output diversi nel tempo, output plausibili possono in realtà essere errati e in rari scenari possono emergere comportamenti inaspettati...
Ciò rende i metodi di test tradizionali insufficienti e talvolta persino impraticabili. L'esempio della calcolatrice è molto simile a quello che si cerca di fare per valutare la prestazione di uno studente in un esame a risposta aperta. Per ogni domanda e per tutti i possibili modi di rispondere, la risposta data è corretta? È al di sopra del livello di conoscenza che lo studente dovrebbe avere? Lo studente ha inventato tutto ma suona molto convincente? Proprio come le risposte ad un esame, I sistemi di intelligenza artificiale possono essere valutati, ma necessitano di un modo più generale e flessibile per adattarsi a input, contesti e casi d'uso diversi. (o tipi di test).
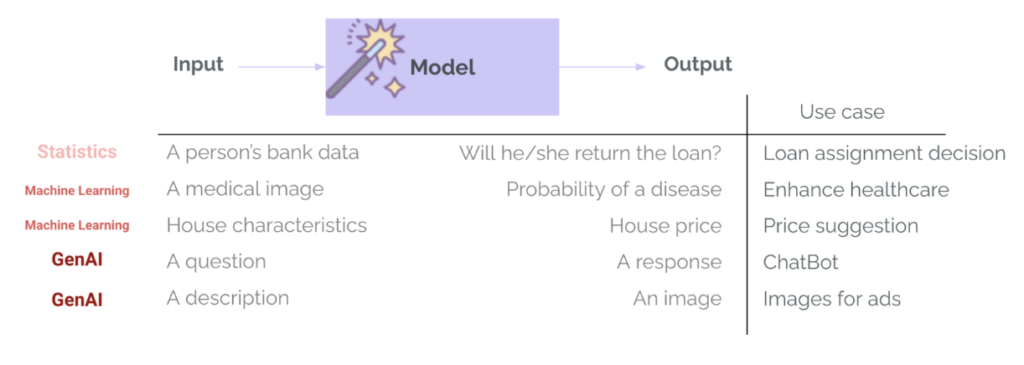
In apprendimento automatico Tradizionalmente (ML), le valutazioni sono già una parte consolidata del ciclo di vita del progetto.. L'addestramento di un modello su un compito specifico, come l'approvazione di un prestito o il rilevamento di una malattia, include sempre una fase di valutazione, utilizzando parametri quali precisione, richiamo, RMSE, MAE... Questo serve a misurare le prestazioni del modello, a confrontare diverse opzioni di modello e a determinare se il modello è sufficientemente valido per passare alla distribuzione. In GenAI, questo in genere cambia: i team utilizzano modelli che sono già stati addestrati e hanno già superato le valutazioni generali effettuate internamente dal fornitore del modello e su benchmark pubblici. Questi modelli sono molto efficaci per compiti generali, come rispondere a domande o scrivere bozze di e-mail, ma c'è il rischio di dar loro troppa fiducia nel nostro caso d'uso specifico. Tuttavia, è importante chiedersi: “Questo fantastico modello è adatto al mio caso d'uso?“È qui che entra in gioco la valutazione.” - Per valutare se le previsioni o le generazioni sono adatte a un caso d'uso, un contesto, degli input e degli utenti specifici.

Un'altra differenza importante tra ML e GenAI è la varietà e la complessità dell'output del modello. Non restituiamo più categorie e probabilità (ad esempio la probabilità che un cliente restituisca un prestito) o numeri (ad esempio il prezzo previsto di una casa in base alle sue caratteristiche). I sistemi GenAI possono restituire molti tipi di output, con lunghezze, toni, contenuti e formati diversi. Allo stesso modo, questi modelli non richiedono più input altamente strutturati e specifici, ma in genere accettano quasi ogni tipo di input: testo, immagini o persino audio o video. Quindi la valutazione diventa molto più difficile.
Perché le valutazioni sono necessarie, non facoltative (a meno che non preferiate le sorprese spiacevoli)
Le valutazioni ti aiutano a misurare se il tuo sistema di intelligenza artificiale funziona effettivamente come previsto. Lo vuoi, se il sistema è pronto per funzionare e, in tal caso, se continua a funzionare come previsto. Di seguito un'analisi del motivo per cui le valutazioni sono importanti:
- Valutazione della qualità: Le valutazioni forniscono un modo strutturato per comprendere la qualità delle previsioni o degli output dell'IA e il modo in cui si integreranno nel sistema generale e nel caso d'uso. Le risposte sono accurate? Utile? Coeso? Imparentato?
- Quantificare gli errori: Le classificazioni aiutano a determinare la percentuale, la tipologia e l'entità degli errori. Con quale frequenza si verificano gli errori? Quali tipi di errori si verificano più frequentemente (ad esempio, falsi positivi, allucinazioni, errori di formato)?
- Mitigazione del rischio: Ti aiuta a individuare e prevenire comportamenti dannosi o parziali prima che raggiungano gli utenti, proteggendo la tua azienda da rischi reputazionali, problemi etici e potenziali problemi normativi.
L'intelligenza artificiale generativa, con relazioni input-output libere e generazione di testo lungo, rende le valutazioni più pertinenti e complesse. Quando le cose vanno male, possono andare molto male. Abbiamo tutti letto titoli su chatbot che offrono consigli pericolosi, modelli che generano contenuti di parte e strumenti di intelligenza artificiale che simulano fatti falsi.
"L'intelligenza artificiale non sarà mai perfetta, ma utilizzando le valutazioni puoi ridurre il rischio di imbarazzo, che potrebbe costarti denaro, credibilità o un momento virale su Twitter."
Come si definisce una strategia di valutazione dell'IA?

Quindi, come determiniamo le nostre valutazioni dell'IA? Non esiste un metodo di valutazione valido per tutti. Le valutazioni dipendono dal caso d'uso specifico e devono essere in linea con gli obiettivi specifici della tua applicazione di intelligenza artificiale. Ad esempio, se stai creando un motore di ricerca, potresti prestare attenzione alla pertinenza dei risultati. Se si tratta di un chatbot, potresti tenere in considerazione l'utilità e la sicurezza. Se è classificato, probabilmente ti interesseranno l'accuratezza e la precisione. Per i sistemi che prevedono più passaggi (ad esempio un sistema di intelligenza artificiale che esegue una ricerca, assegna priorità ai risultati e quindi genera una risposta), è spesso necessario valutare ogni passaggio. L'idea qui è misurare se ogni passaggio contribuisce a raggiungere il parametro di successo complessivo (e da qui capire dove concentrare iterazioni e miglioramenti).
Le aree di valutazione comuni includono:
- Correttezza e allucinazioni: I risultati sono realisticamente accurati? Il sistema genera informazioni errate o allucinazioni?
- Rilevanza: Il contenuto è coerente con la query dell'utente o con il contesto fornito?
- sicurezza, pregiudizi e tossicità
- Formato: L'output è nel formato previsto (ad esempio, JSON, chiamata di funzione valida)?
- Sicurezza, pregiudizi e tossicità: Il sistema genera contenuti dannosi, parziali o tossici?
Parametri specifici per attività. Ad esempio, nelle attività di classificazione vengono utilizzate metriche quali accuratezza e precisione, nelle attività di riepilogo ROUGE o BLEU e nelle attività di generazione di codice regex e di verifica dell'esecuzione senza errori.
Come vengono calcolate effettivamente le valutazioni?
Una volta stabilito cosa si desidera misurare, il passo successivo è progettare i casi di test. Questo sarà un insieme di esempi (più sono, meglio è, ma sempre bilanciando valore e costi) in cui avrai:
- Esempio di input:Un'introduzione realistica del tuo sistema una volta entrato in produzione.
- Risultati attesi (Se applicabile): fatto chiave o esempio dei risultati desiderati.
- Metodo di valutazione: Meccanismo di registrazione per la valutazione del risultato.
- Risultato o successo/fallimento: Una metrica calcolata che valuta il caso di prova.
A seconda delle esigenze, del tempo e del budget, puoi utilizzare diverse tecniche come metodi di valutazione:
- Strumenti di registrazione statistica quali: BLEU, ROUGE e METEOR, ovvero misura della similarità del coseno tra incorporamenti: utili per confrontare il testo generato con l'output di riferimento.
- Metriche tradizionali di apprendimento automatico come Precisione, richiamo e AUC: ideali per la classificazione con dati etichettati.
- Modello linguistico di grandi dimensioni come giudice (LLM-as-a-Judge) Utilizzare un modello linguistico di grandi dimensioni per valutare l'output (ad esempio, "Questa risposta è corretta e utile?"). Particolarmente utile quando non sono disponibili dati non classificati o quando si valuta un costrutto aperto.
Valutazioni basate sul codice Utilizzare espressioni regolari, regole logiche o implementazione di casi di test per convalidare i formati.
La linea di fondo
Mettiamo insieme il tutto con un esempio concreto. Immagina di creare un sistema di analisi del sentiment per aiutare il tuo team di assistenza clienti a stabilire la priorità delle email in arrivo.
L'obiettivo è garantire che i messaggi più urgenti o negativi ricevano risposte più rapide, riducendo la frustrazione, aumentando la soddisfazione e abbassando il tasso di abbandono dei clienti. Si tratta di un caso d'uso relativamente semplice, ma anche in un sistema come questo, con output limitato, la qualità è importante: previsioni errate potrebbero portare ad assegnare priorità casuali alle e-mail, il che significa che il tuo team sta perdendo tempo con un sistema che costa denaro.
Quindi, come fai a sapere se la tua soluzione funziona come desideri? Stai valutando. Ecco alcuni esempi di cose che potrebbero essere rilevanti da valutare in questo specifico caso d'uso:
- Convalida del formato: Gli output di una chiamata a un modello linguistico di grandi dimensioni (LLM) per prevedere il sentiment delle email vengono restituiti nel formato JSON previsto? Ciò può essere valutato tramite controlli basati sul codice: espressioni regolari, convalida dello schema, ecc.
- Precisione della classificazione del sentimento: Il sistema classifica correttamente il sentimento in una gamma di testi: brevi, lunghi e multilingue? Ciò può essere valutato utilizzando dati etichettati mediante metriche di apprendimento automatico tradizionali (metriche ML) oppure, se le etichette non sono disponibili, utilizzando un modello linguistico di grandi dimensioni (LLM) come giudice.
Una volta che la soluzione è attiva, vorrai anche includere le metriche più strettamente correlate all'impatto finale della tua soluzione.:
- Efficacia della definizione delle priorità: Gli addetti all'assistenza vengono effettivamente indirizzati alle email più importanti? La definizione delle priorità è in linea con l'impatto aziendale desiderato?
- Impatto aziendale finale: Nel tempo, questo sistema riduce i tempi di risposta, diminuisce il tasso di abbandono dei clienti e migliora i punteggi di soddisfazione?
Le valutazioni sono essenziali per garantire che i sistemi di intelligenza artificiale siano utili, sicuri, preziosi e pronti per gli utenti in produzione. Quindi, che tu stia lavorando con un semplice classificatore o con un chatbot aperto, prenditi il tempo di definire cosa significa "abbastanza buono" (qualità minima praticabile) e costruisci delle valutazioni attorno a questo per misurarlo!
Riferimenti
[1] Il tuo prodotto di intelligenza artificiale ha bisogno di valutazioniHamel Husain
[2] Metriche di valutazione LLM: la guida definitiva alla valutazione LLM, Confident AI
[3] Valutazione degli agenti di intelligenza artificiale, deeplearning.ai + Arize
I commenti sono chiusi.