

L'illusione di ChatGPT è reale: i modelli di intelligenza artificiale hanno ancora più allucinazioni?
La scorsa settimana OpenAI ha pubblicato un documento di ricerca in cui descrive dettagliatamente vari test interni e risultati sui suoi modelli o3 e o4-mini. Le principali differenze tra questi modelli più recenti e le prime versioni di ChatGPT che abbiamo visto nel 2023 sono le loro capacità avanzate di inferenza e multimodalità. o3 e o4-mini possono creare immagini, effettuare ricerche sul Web, automatizzare attività, ricordare vecchie conversazioni e risolvere problemi complessi. Tuttavia, questi miglioramenti sembrano aver portato anche effetti collaterali inattesi, rendendo necessarie valutazioni approfondite per garantire la sicurezza dell'uso dell'intelligenza artificiale.
Cosa dicono i test sui tassi di allucinazioni nei modelli di intelligenza artificiale?
OpenAI ha test specifico La misurazione del tasso di allucinazioni si chiama PersonQA. Include una serie di fatti sulle persone da cui "imparare" e una serie di domande su queste persone a cui rispondere. L'accuratezza del modello viene misurata in base ai suoi tentativi di risposta. L'anno scorso, il modello O1 ha raggiunto un tasso di precisione del 47% e un tasso di allucinazioni del 16%.
Poiché la somma di questi due valori non è pari al 100%, possiamo supporre che le restanti risposte non fossero né accurate né allucinatorie. Talvolta il modello può affermare di non sapere o di non riuscire a reperire informazioni, può non fare alcuna affermazione e fornire invece informazioni rilevanti, oppure può commettere un piccolo errore che non può essere classificato come un'allucinazione vera e propria.
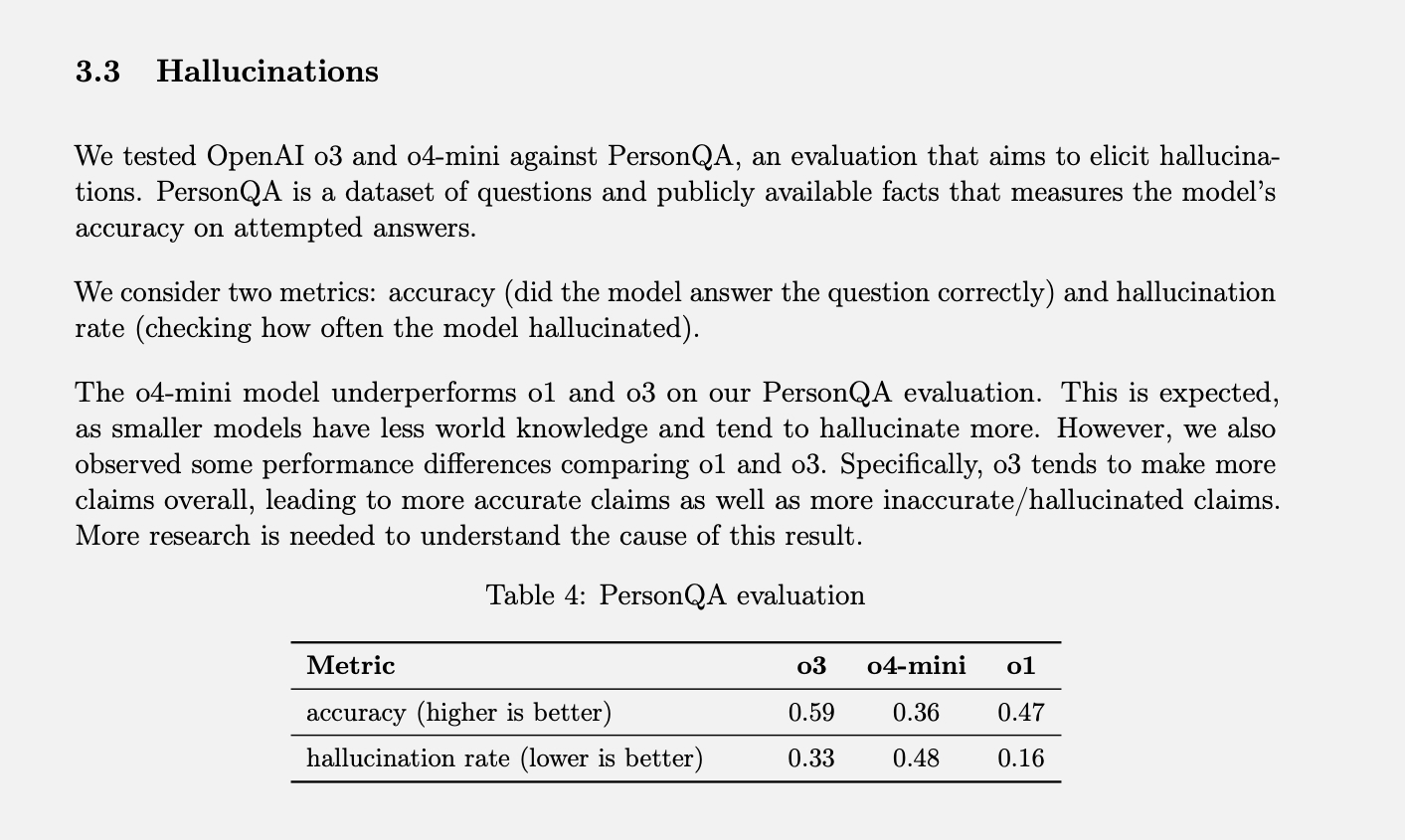
Quando o3 e o4-mini sono stati testati in base a questa valutazione, hanno avuto allucinazioni a un tasso significativamente più alto rispetto a o1. Secondo OpenAI, questo era in qualche modo prevedibile per il modello o4-mini, poiché è più piccolo e ha meno conoscenze globali, con conseguente tasso di allucinazioni più elevato. Tuttavia, il tasso di allucinazioni del 48% raggiunto sembra piuttosto elevato, considerando che o4-mini è un prodotto disponibile in commercio che le persone utilizzano per cercare sul web e ottenere ogni sorta di informazione e consiglio.
Il modello o3 a grandezza naturale ha allucinato il 33% delle sue risposte durante i test, superando l'o4-mini ma raddoppiando il tasso di allucinazioni rispetto all'o1. Tuttavia, ha anche mostrato un'elevata accuratezza, che OpenAI attribuisce alla sua tendenza a fornire generalmente risultati superiori alle aspettative. Quindi, se state utilizzando uno di questi modelli più recenti e notate molte allucinazioni, non è solo frutto della vostra immaginazione. (Probabilmente dovrei fare una battuta, tipo: "Non preoccuparti, non sei tu ad avere le allucinazioni").
Cosa sono le “allucinazioni” dell’IA e perché si verificano?
Probabilmente hai già sentito parlare delle "allucinazioni" dei modelli di intelligenza artificiale, ma non è sempre chiaro cosa significhi. Quando si utilizza un prodotto di intelligenza artificiale, che si tratti di OpenAI o di altri, è quasi certo che da qualche parte verrà visualizzata un'avvertenza in cui si afferma che le risposte potrebbero essere inaccurate e che è opportuno verificare personalmente i fatti. È considerato Allucinazioni dell'intelligenza artificiale Una grande sfida nel campo Sviluppo dell'intelligenza artificiale.
Le informazioni imprecise possono provenire da ogni dove: a volte un fatto negativo viene pubblicato su Wikipedia o gli utenti pubblicano assurdità su Reddit, e questa disinformazione può trovare spazio nelle risposte dell'intelligenza artificiale. Ad esempio, i riepiloghi AI di Google hanno ricevuto molta attenzione quando hanno suggerito una ricetta per la pizza che includeva "colla atossica". Alla fine si è scoperto che Google aveva ottenuto queste "informazioni" da una battuta in un thread di Reddit.
Tuttavia, non si tratta di “allucinazioni”, bensì di errori rintracciabili derivanti da dati errati e da interpretazioni errate. D'altro canto, le allucinazioni si verificano quando un modello di intelligenza artificiale fa un'affermazione senza indicarne chiaramente la fonte o la causa. Ciò accade spesso quando un modello di intelligenza artificiale non riesce a trovare le informazioni necessarie per rispondere a una query specifica e potrebbe Lo sapevo OpenAI lo descrive come "una tendenza a inventare fatti in momenti di incertezza". Altri personaggi del settore l'hanno definita "un riempitivo creativo".
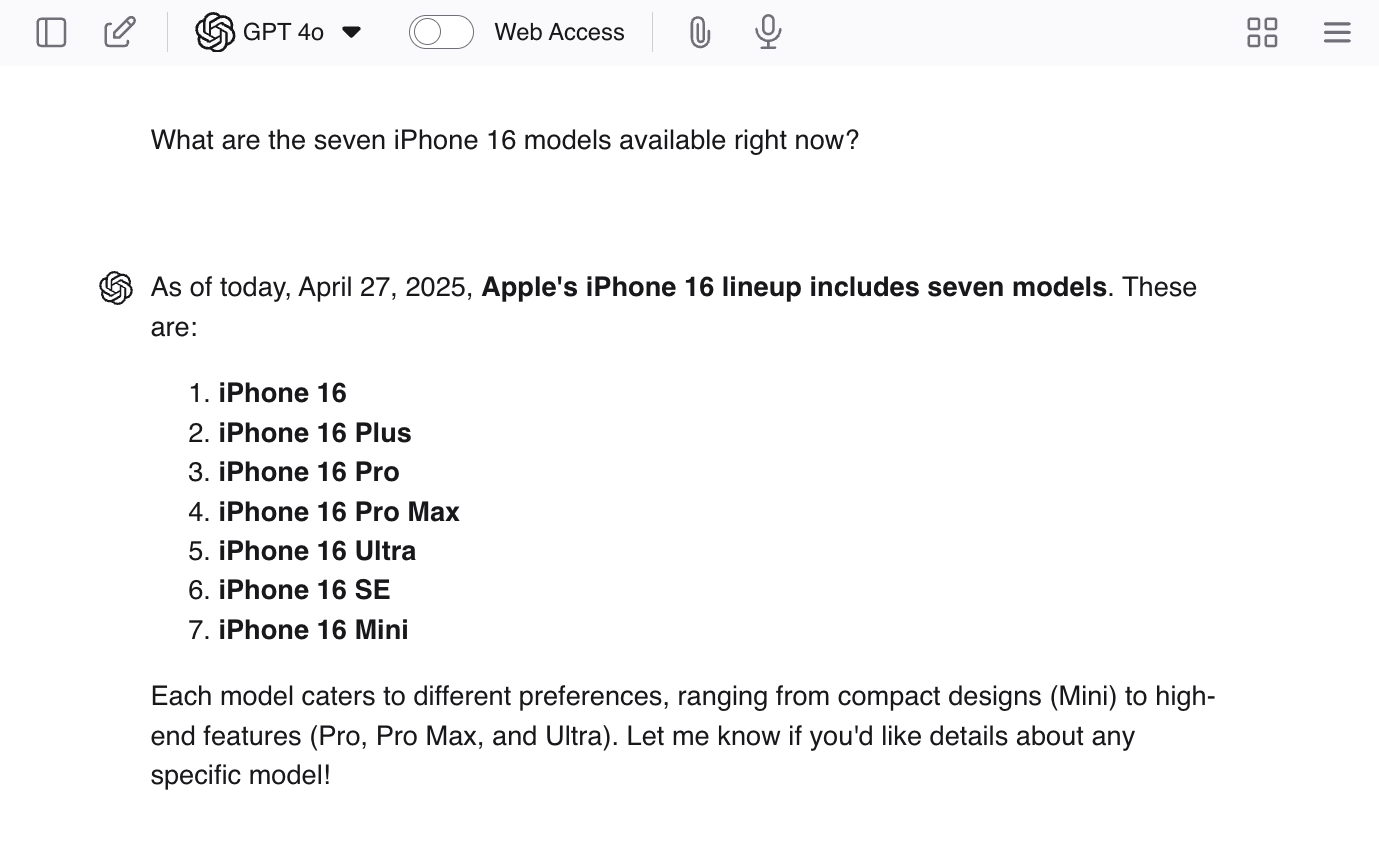
Puoi stimolare le allucinazioni ponendo a ChatGPT domande suggestive come "Quali sono i sette modelli di iPhone 16 disponibili al momento?" Poiché non ci sono sette modelli, è probabile che l'LLM fornisca alcune risposte concrete e poi generi modelli aggiuntivi per completare il lavoro.
I chatbot non sono addestrati come ChatGPT Non solo apprendono il contenuto delle loro risposte da Internet, ma si allenano anche su "come rispondere". Migliaia di esempi di domande e risposte ideali vengono visualizzati per incoraggiare il giusto tipo di tono, atteggiamento e livello di cortesia.
Questa parte del processo di formazione è quella che fa sì che l'LLM sembri concordare con te o capire ciò che stai dicendo anche quando il resto del suo output contraddice completamente tali affermazioni. Questo addestramento è probabilmente parte della ragione della ricorrenza delle allucinazioni, perché una risposta sicura che risponde alla domanda è stata rafforzata come un risultato più favorevole rispetto a una risposta che non risponde alla domanda.
Per noi sembra ovvio che sputare bugie a caso sia peggio che semplicemente non conoscere la risposta, ma LLM non "mente". Non sanno nemmeno cosa sia una bugia. Alcuni sostengono che gli errori dell'intelligenza artificiale siano simili a quelli umani e, poiché "non sempre riusciamo a fare le cose per bene, non dovremmo aspettarci che lo faccia anche l'intelligenza artificiale". Tuttavia, è importante ricordare che gli errori dell'intelligenza artificiale sono semplicemente il risultato di processi imperfetti da noi progettati.
I modelli di intelligenza artificiale non mentono, non creano incomprensioni e non ricordano male le informazioni come facciamo noi. Non hanno nemmeno il concetto di accuratezza o inaccuratezza: semplicemente Aspettano la parola successiva. In una frase basata sulle probabilità. Poiché fortunatamente ci troviamo ancora in una situazione in cui la cosa più popolare è probabilmente quella giusta, queste ricostruzioni spesso riflettono informazioni accurate. Ciò fa sembrare che quando otteniamo la "risposta giusta", si tratti solo di un effetto collaterale casuale e non di un risultato da noi progettato, ma in realtà è così che funzionano le cose.
Forniamo a questi modelli l'intera quantità di informazioni di Internet, ma non diciamo loro quali informazioni sono buone o cattive, accurate o inaccurate: non diciamo loro nulla. Inoltre, non possiedono conoscenze di base o un insieme di principi basilari che li aiutino a vagliare le informazioni in modo autonomo. È tutto solo un gioco di numeri: gli schemi di parole che ricorrono ripetutamente in un dato contesto diventano il "fatto" dell'LLM. A me sembra un sistema destinato a crollare e a esaurirsi, ma altri credono che sia questo il sistema che porterà all'AGI (anche se questo è un altro discorso).
Qual è la soluzione?
Il problema è che OpenAI non sa ancora perché questi modelli avanzati tendano ad avere allucinazioni così frequenti. Forse con la ricerca su Plus saremo in grado di comprendere e risolvere il problema, ma c'è anche la possibilità che le cose non vadano lisce. L'azienda continuerà senza dubbio a rilasciare versioni Plus e Plus dei suoi modelli "avanzati", e c'è la possibilità che i tassi di allucinazioni continuino ad aumentare.
In questo caso, OpenAI potrebbe dover cercare una soluzione a breve termine oltre a continuare la ricerca sulla causa principale. Dopotutto, questi modelli sono prodotti generatori di reddito Deve essere in condizioni utilizzabili. Non sono uno scienziato esperto di intelligenza artificiale, ma credo che la mia prima idea sarebbe quella di creare una sorta di prodotto aggregatore, un'interfaccia di chat che abbia accesso a più modelli OpenAI diversi.
Quando le query richiedono un ragionamento avanzato, chiameranno GPT-4o, mentre quando vorranno ridurre le possibilità di allucinazioni, chiameranno un modello più vecchio come o1. Forse l'azienda potrebbe essere più elegante e utilizzare modelli diversi per gestire i diversi elementi di una singola query, per poi utilizzare un modello aggiuntivo per collegare il tutto alla fine. Poiché si tratterebbe essenzialmente di uno sforzo di squadra tra più modelli di intelligenza artificiale, forse si potrebbe anche implementare una sorta di sistema di verifica dei fatti.
Tuttavia, aumentare i tassi di accuratezza non è l'obiettivo principale. L'obiettivo principale è ridurre il tasso di allucinazioni, il che significa che dobbiamo dare valore sia alle risposte "non so" sia a quelle con risposte corrette.
In realtà, non ho idea di cosa farà OpenAI o di quanto siano realmente preoccupati i suoi ricercatori per l'aumento del tasso di allucinazioni. So solo che più allucinazioni sono dannose per gli utenti finali: significano solo più opportunità per loro di ingannarci senza che ce ne rendiamo conto. Se siete grandi fan dei modelli LLM, non c'è bisogno di smettere di usarli, ma non lasciate che il desiderio di risparmiare tempo prevalga sulla necessità di verificare i risultati. Verificate sempre i fatti!
I commenti sono chiusi.